

-
使用R语言进行混合线性模型(mixed linear model) 分析代码及详解2020-01-01统计学和语言计量研究 认知语言学本篇转载自微信公众号:荷兰心理统计联盟,推送的是《使用R语言进行混合线性模型(mixed linear model) 分析代码及详解》,敬请品读!
使用R语言进行混合线性模型(mixed linear model) 分析代码及详解
转载自微信公众号:1.混合线性模型简介
混合线性模型,又名多层线性模型(Hierarchical linear model)。它比较适合处理嵌套设计(nested)的实验和调查研究数据。此外,它还特别适合处理带有被试内变量的实验和调查数据,因为该模型不需要假设样本之间测量独立,且通过设置斜率和截距为随机变量,可以分离自变量在不同情境中(被试内设计中常为不同被试)对因变量的作用。
简单的说,混合模型中把研究者感兴趣的自变量对因变量的影响称为固定效应,把其他控制的情景变量称为随机效应。由于模型中包括固定和随机效应,故称为混合线性模型。无论是用方差分析进行差异比较,还是回归分析研究自变量对因变量的影响趋势,混合线性模型比起传统的线性模型都有更灵活的表现。
今天我们就来使用R语言进行混合线性模型分析及制图。
2.分析过程
假如我们有一组数据来描述饮啤酒次数对微笑次数的影响,我们调查了本地15个酒吧,将饮酒次数最为自变量,微笑次数作为因变量读入R并作散点图估计二者的关系。可以看到,在不考虑酒吧这个场景因素的情况之下,二者呈负相关的关系(如图1),之后的相关分析也证明了这一点(如图2)。
图1:饮酒次数和微笑频率的散点图
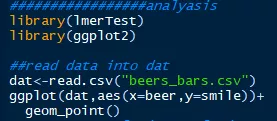

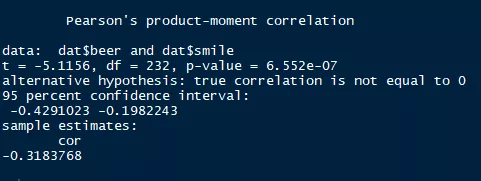
图2:相关分析结果

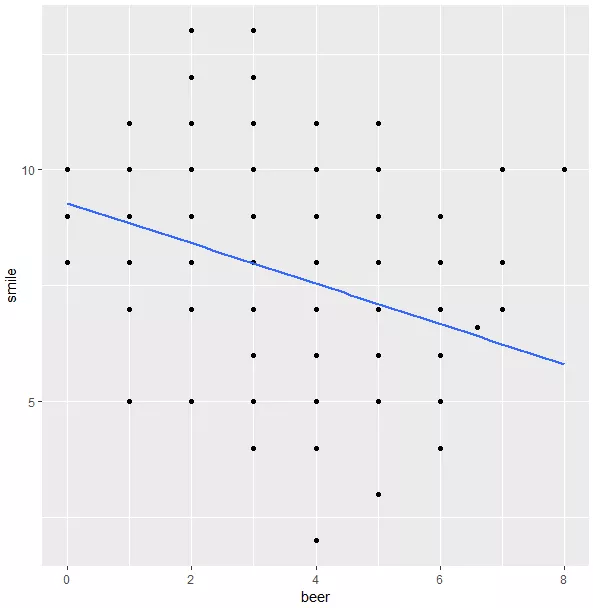
如果这时我们直接对而者的关系进行线性回归建模,得到的模型如图3:
然而,当我们把酒吧这一变量作为随机变量纳入,并随机估计每一个酒吧的截距和斜率时,自变量和因变量的相关关系也随之出现了变化,如图4:
图4:将酒吧的截距和斜率随机估计之后的模型作图
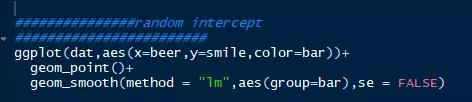

从上图中我们可以看出,当控制了“情景变量”酒吧时,自变量和因变量的关系完全改变了。反观我们日常收集到的研究数据,大多数也是嵌套(nested)在这样的情景变量之中(比如被试内设计中的个体差异,每一个被试相对于一系列实验操作而言,都可以看作是一个情景变量的水平),当忽视情景变量的作用时,可能会出现无法解释的分析结果。
接下来在这个线性模型中加入随机效应项(一般包括情景变量的斜率和截距。所谓截距即当自变量为0时,因变量的平均值。而斜率指的是每增加一个单位的自变量,因变量的增加值)。就在线性模型中加入多少随机效应项而言,一些学者认为应该采用渐进递增的方式进行,即从每一个随机效应项的截距到斜率逐渐叠加到已有模型,并使用卡方检验比较AIC和BIC等参数是否有显著提升来判断模型是否为最优(如Andy Field在他的Discovering statistics using R 一书最后一章中介绍的方法)。
然而,另一些学者认为这样会增加模型的误差并且增大一类错误的概率(barr et.al, 2013)。他们提倡一次性将所有“符合逻辑”的随机效应项一次性纳入模型当中,再检验这些随机效应项对模型估计方差的影响。如果影响小,再剔除这些随机效应项。然而若增加了过多的随机效应项,会使得模型自由度减少而有降低统计检验力的风险。
我们选择后一种方式来进行模型建构。首先,使用lmerTest包中的lmer功能进行模型估计,然后使用summary输出结果。如图5,在这个功能的formula当中,1 表示随机估计每个bar中beer对smile影响截距,“beer|bar”表示随机估计不同bar中,中beer对smile影响的斜率。
图5:随机估计在不同酒吧上的斜率和截距后的分析


可以在输出的random effects中看出,截距的方差估计为7.87左右而斜率的方差估计只有0.02左右,可以预见随机估计斜率对模型的优化并不明显。故去掉随机斜率项后再做上述分析,如图6。
图6:去掉随机斜率项之后的分析


为了验证去掉随机斜率项之后对模型确实没有显著影响,我们通过anova比较两个模型,卡方检验发现二者确实没有显著差异,如图7:


因此可以认为仅将bar变量的截距作为随机效应项的模型为最优模型。接下来我们可以通过sjstats安装包的功能来求其他混合线性模型的重要参数。例如解释率R2(可以当作效果量的指标,越大越好),ICC(全称为intraclass correlation, 指情景(随机)变量分类的相关性,越高说明情景变量的分类对因变量影响越大),AIC(模型优化的指标,越低越好,该功能为R核心包的自带函数)具体如图8:
图8:最优模型其他重要参数的计算
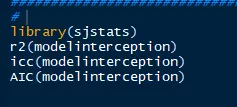
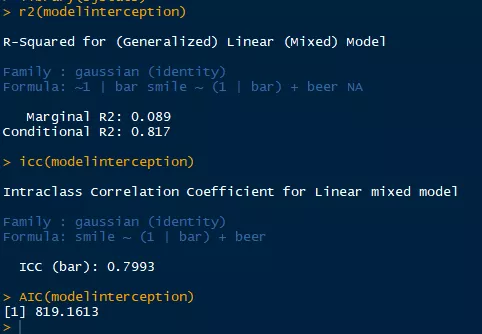
PS:Marginal R2为固定效应(及感兴趣的自变量)对因变量的解释率,而Conditional R2 为模型整体(包括随机效应项)对因变量的解释率。
3.自变量为因素型的分类变量(方差分析)
上述分析过程介绍了自变量为连续变量时如何建立混合线性模型的基本思路。当自变量为因素型类别变量时,也可以上述思路进行模型建构,并可直接通过找到的最佳线性模型的自变量系数检验来判断主效应和交互效应是否显著。然后再进行事后检验即可。
参考文献:
Field, A., Miles, J., & Field, Z. (2012). Discovering statistics using R. Sage publications.
Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of memory and language, 68(3), 255-278.
本篇作者:覃恺洋
后台回复Mixed 获取本期示例代码和数据
----
欢迎关注我们
一个专注于心理学及管理学领域统计方法(复杂模型Mplus及R软件的应用)及英文写作的公众号
----
另如果涉及统计及代码问题,请在文章下方留言或邮寄uunotebook@163.com。公众号回复48小时就无法回复了。
 1103 0 0
1103 0 0- 关注作者
- 私信作者
- 转 发
- 加入收藏

- 热门文章
-
 Praat英文教程——Speech Signal P...2019-12-19
Praat中文教程-熊子瑜老师2004版《Pr...2019-12-19
Praat英文教程——Speech Signal P...2019-12-19
Praat中文教程-熊子瑜老师2004版《Pr...2019-12-19 黄丽娜《助听器问卷的跨文化翻译和适用...2020-02-04
罗润芬等《加速康复外科护理在小儿人工...2020-02-04
黄丽娜《助听器问卷的跨文化翻译和适用...2020-02-04
罗润芬等《加速康复外科护理在小儿人工...2020-02-04
- 最新文章
-
 AN INTRODUCTION...2020-05-06
AN INTRODUCTION...2020-05-06 R语言和Jspsych编写本地和在...2020-02-16
R语言和Jspsych编写本地和在...2020-02-16 【科普短文】P300事件相关电位...2020-02-09
【科普短文】P300事件相关电位...2020-02-09
- 技术支持
-
管理员微信
 电话:010-82185409邮箱:service@phonetics.com.cn
电话:010-82185409邮箱:service@phonetics.com.cn京ICP备18027836号-11 京公网安备 11010802032611号