

-
李培凯:九种方法筛选无效问卷及对研究设计的启示2019-12-22本文转载自微信公众号:荷兰心理统计联盟,推送的是荷兰乌特勒支大学工业组织心理学在读博士生李培凯的原创文章《九种方法筛选无效问卷及对研究设计的启示》,敬请大家品读。
李培凯:九种方法筛选无效问卷及对研究设计的启示
转载自微信公众号:随着网络及智能手机的普及,传统的一些纸笔测验渐渐被网络问卷所替代。网络问卷由于其便捷性,很大程度上方便了研究者和被试。2018年JOM一篇文章发现越来越多的研究者开始使用网络问卷收集数据,相关发表的文章也呈现逐年增加的趋势(参见Porter, Outlaw, Gale, & Cho, 2018)。且很多文章都发表在领域内比较好的刊物,如AMJ (53), ASQ(12), JAP高达130多篇。
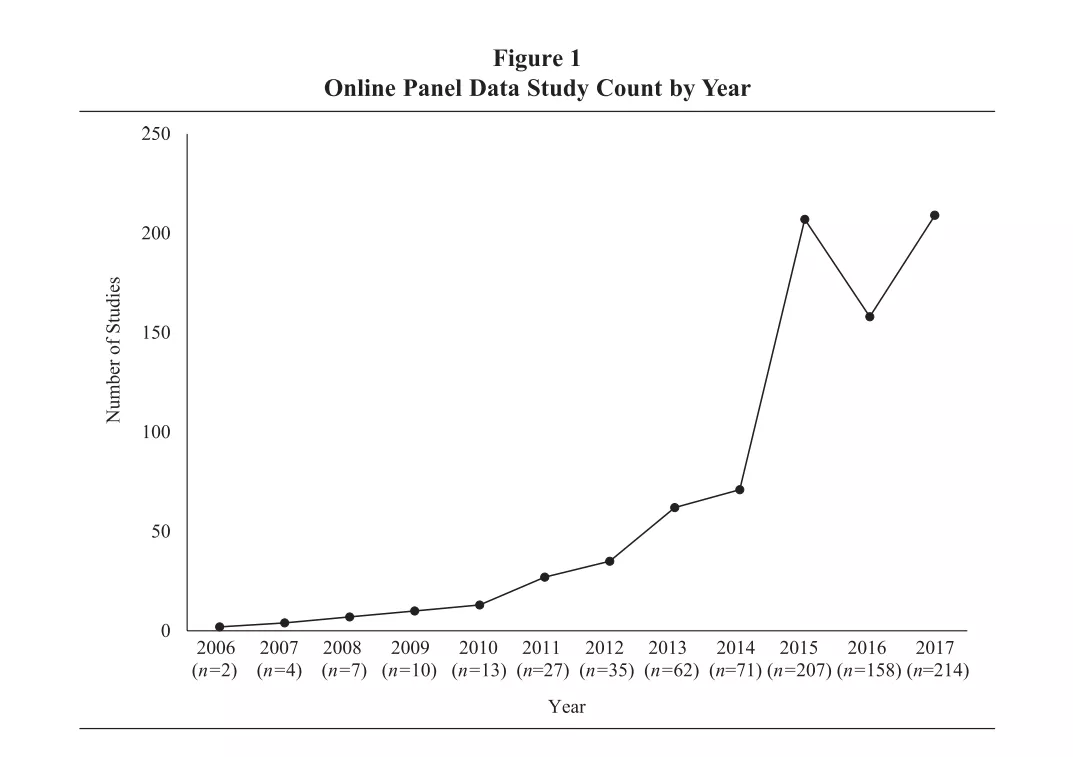

图片来源:Porter, C. O. L. H., Outlaw, R., Gale, J. P., & Cho, T. S. (2018). The Use of Online Panel Data in Management Research: A Review and Recommendations. Journal of Management
然而,网络问卷调查最大的问题在于研究者不能直接观察被试,对于被试是否认真作答完全不知情。虽然你可以设定每个题目为必填项(这样也就没有了“缺失值”),但你无法得知被试有没有读指导语和题目,甚至极大可能只是随便填写。
你也可以控制作答时间,比如某一页设置至少多少秒。我们的被试也很聪明,不可能直接填写5555555555555……这样的循环。如果是123411234呢?即便你一眼就可以识别有50个5或者20个1234类似的重复,如果你有500问卷,是要一个个去看?
还有的人可能填写345345345,或者不时调整换个数字,中间间隔几个不一样,这样根本不看题目,完全无意义的作答,你的研究又有何用?所以,数据筛选很有必要。
Porter 等人2018年JOM那篇文章对于网络数据库使用建议中也明确提到数据筛选, attention check(见下图)。


可以预料,随着越来越多研究者使用online data,随后的审稿及发表对于数据筛选会越来越重视。所以,不如趁早学习一些方法,即便不知道是不是真有用(可以持保留态度),但至少不要让审稿人在数据筛选给你文章挑刺。科学筛选数据也会一定程度上增加我们研究设计的严谨性。本文将介绍九种常见的数据筛选方式,并教你如何用统计软件实现(而非肉眼去看)。
需要说明一点:下文所提方法基于5篇核心文献。如果有遗漏更好的办法,欢迎分享~

在谈具体筛选无效被试方法之前,我们先看看哪些因素可以影响被试是否认真作答。Meade 和 Craig (2012) 发在Psychology Methods 上的文章提到,四个因素可以影响(Factor influence vareless responses):
1. Interest 被试是否感兴趣
(很多心理学研究让本科生参与问卷调查只是换取学分,很难说被试对研究感兴趣),对应的可以use incentives,比如钱……
2. Survey Length 问卷的长度
避免太长,将心比心,问卷越长大家越不耐烦,越容易出现胡乱填写。
3. Social Contact 社会接触
被试与研究者之间是否能面对面交流。显然在线问卷调查很难实现这点。
4. Environmental Distraction
周围环境的干扰
比如被试可能只是在地铁上,上下班无聊,顺便随手填个问卷,还能挣个晚饭。。。外部环境的干扰肯定会影响作答质量,这也是心理学实验为什么要在实验室进行,小房间什么也没有只有一台电脑,以尽可能减少干扰。
研究设计的启示:
1. Using longer items
2. Using both positive and negative wording
3. If possible observe the participants & time their response (e.g., online)(DeSimone, Harms, & & DeSimone, 2015)
你已经付了被试费,然而不能见你的被试,问卷的长度也控制到100题左右。然而,那么接下来的问题是如何筛选不认真作答被试呢?
简单而言可以通过两种方式:其一是在问卷设计时候插入一些筛选题目;其二是数据收集完成之后通过一些统计方法进行识别和筛选。Generally two types: Study design and psot-hoc analysis (Meade & Craig, 2012). 最主要的三种非干扰方法为:recording response time(Behrend, Sharek, Meade, &Wiebe, 2011; Berry et al., 1992),
the number of consecutive identical responses provided by the respondent(“longstring”; Behrend et al., 2011; Huang et al., 2012; Meade & Craig, 2012), andindividual response variability (IRV; Dunn, Heggestad, Shanock, & Nels, in press).
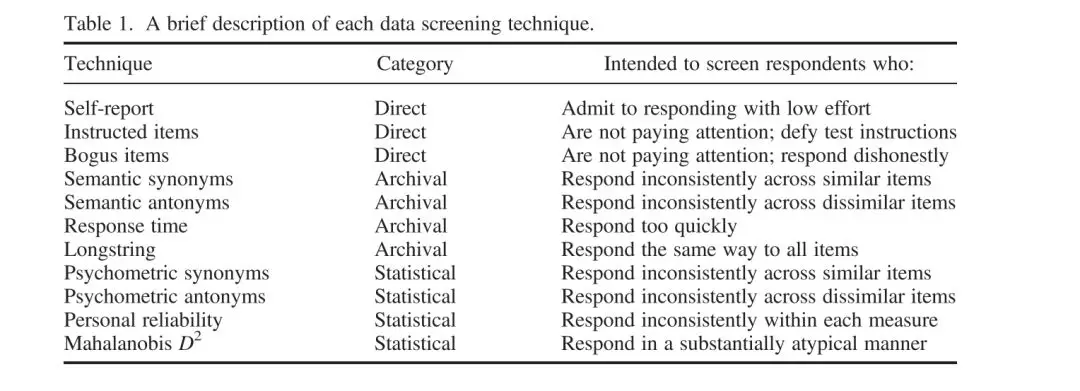
DeSimone et al., 2015
甄别方法主要包括两种:
问卷设计法
方法1
诈选题(Bogus items)
方法2
指定选项题目(Instructed items)
方法3
自我报告是否认真作答 (self-reported diligence)
统计分析法
方法4
作答时间 (response time)
方法5
奇数偶数题目作答一致性(Even-Odd Consistency measure)
方法6
连续相同作答分析(LongString Analysis)
方法7
异常值分析(multivariate outlier analysis)
方法8
问卷法:社会赞许和撒谎问卷 (social desirability & lie scale)
方法9
语义相近题目作答的一致性 (Semantic synonyms)
注:为了便于大家后期自己研究中便于引用出处,下文会用中英文,注明参考文献。
方法一:诈选题(Bogus items)
Bogus items contain content that is either obvious or ridiculous.
利用一些事实上明显不成立或者错误的信息,如果被试错选则有可能没有认真看题。
“I was born on February 30”
“I have exactly 354 best friends”
“I have 17 fingers on my left hand”
“I was born on planet Earth.” (DeSimone et al., 2015)
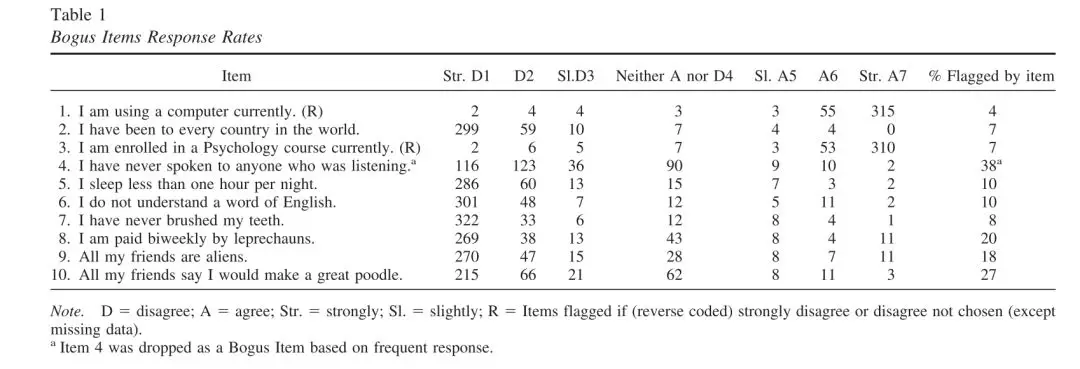
来源:(Meade & Craig, 2012)
“I have never used a computer”; (Huang et al., 2014).
1. 我从未使用过手机
I have never used a mobile phone (Huang et al., 2014))
2. 妖精们每两周付我一次钱
I am paid biweekly by leprechauns (Meade & Craig, 2012).
3. 我所有的朋友都说我是一个很棒的哈巴狗
All my friends say I would make a great poodle (Meade & Craig, 2012)
(1 = strongly disagree, 7 = strongly agree)
correct answers to “I am paid biweekly by leprechauns” may be ‘strongly disagree’ and ‘disagree.’
Incorrect answers may include ‘slightly disagree,’ ‘neither agree nor disagree,’ and all of the identically mirrored ‘agree’ options. (Curran, 2016)
不认真作答的被试可能选择:既非同意也非不同意, 中立,同意,非常同意
Warning: 该方法有风险,有时候被试觉得好玩,甚至自认为有幽默感可能故意选择同意……
方法二:指定选项题目(Instructed items)
顾名思义,就是指定选择某个选项。
One common and fairly transparent technique instructs respondents to answer with a particular response option, such as “Please select Moderately Inaccurate for this item” (Huang et al., 2012).
例: 此题请选C;
“Please indicate option [X] for this question” (DeSimone, Harms, & & DeSimone, 2015)
“To monitor quality, please respond with a two for this item”.
此题,请留白:“Please leave this item blank”. (DeSimone et al., 2015)
鉴于被试注意力会起伏不定,建议设置多个指定选项题目。
Researchers should be aware that respondents may fluctuate in effort throughout the survey. Consequently, it is advisable to insert multiple instructed items into a survey (DeSimone et al., 2015)
Warning: 以上两种方法对于完全不看题目和选项的被试有效,但是对于故意扭曲答案的被试不起作用。
Bogus and instructed items are useful for identifying inattentive participants, but may be less suitable for identifying respondents who intentionally distort their responses (DeSimone, Harms, & & DeSimone, 2015).
方法三:自我报告是否认真作答 (self-reported diligence)
直接问被试有没有认真回答。
Self-report indices generally appear in the form of a question (or series of questions) at the end of a survey addressing attention, effort, or thoughtfulness. Although straightforward, a major limitation lies in the transparency of this technique, rendering it vulnerable to dishonesty and demand characteristics (DeSimone et al., 2015).
1. Instruction:“I verify that I have carefully and honestly answered all questions on this survey.” (Meade & Craig, 2012)
2. “Lastly, it is vital to our study that we only include responses from people that devoted their full attention to this study. Otherwise years of effort (the researchers’ and the time of other participants) could be wasted. You will receive credit for this study no matter what, however, please tell us how much effort you put forth towards this study.”
“I put forth ____ effort towards this study”
with response options of 1 = “almost no,” 2 = “very little,” 3 = “some,” 4 = “quite a bit,” and 5 = “a lot of.” (Meade & Craig, 2012)
3. “Also, often there are several distractions present during studies (other people, TV, music, etc.). Please indicate how much attention you paid to this study. Again, you will receive credit no matter what. We appreciate your hon- esty!” SRSI Attention was then assessed as the response to the item
“I gave this study ____ attention”
with options 1 = “almost no,” 2 = “very little of my,” 3 = “some of my,” 4 = “most of my,” and 5 = “my full.” (Meade & Craig, 2012)
4. “In your honest opinion, should we use your data in our analyses in this study?”
1 = “yes” or 0 = “no” response. (Meade & Craig, 2012)
5. “I occasionally answered items without reading them.” (DeSimone et al., 2015).
6. “I carefully considered each item before responding”; Berry et al., 1992; Costa & McCrae, 1997),
这也是基于被试“诚实”假定下才有效 ……
方法四:作答时间 (response time)
Using response time as a screening technique relies on the assumption that there is a minimum amount of time that respondents must spend on an item in order to answer accurately. Although variations in reading speed and item length make cutoff scores difficult to justify, it is “unlikely for participants to respond to survey items faster than the rate of 2 s per item” (Huang, Curran, Keeney, Poposki & DeShon, 2012, p. 106).
The response time screen was computed using the average number of seconds required to complete each item. For example, a score of 1.0 indicates that the participant required 1 s/item while a score of 2.5 indicates that the participant required 2.5 s/item (DeSimone et al., 2015).
Kurtz and Parish (2001). Examining self-report and response time measures indicated that their use to screen the data is better than doing nothing.
统计实现:现在网络作答都会有response time, 但是这种只有在没有设定强制作答时间才有效。分析时利用SPSS, Mplus等软件只需描述性统计,查看Minimum 作答时间,筛选出每道题小于2s的被试。
方法五:奇数偶数题目作答一致性(Even-Odd Consistency measure)
简而言之,就是个人作答题号奇数偶数题的一致性,其做法是将单维度问卷分成两半,然后计算相关系数。
An additional index recommended by Jackson (1976, as cited in Johnson, 2005) was examined which we termed the Even-Odd Consistency measure. With this approach, unidimensional scales are divided using an even-odd split based on the order of appearance of the items. An even subscale and also an odd subscale score is then computed as the average response across subscale items. A within-person correlation is then computed based on the two sets of subscale scores for each scale. (Meade & Craig, 2012)
The correlation was then corrected for decreased length using the Spearman–Brown formula. Low individual reliability indicated IER (Huang et al., 2012).
统计方法:将单维问卷拆分成奇数偶数题目,计算相关系数,系数较低的可能(非必然)为不认真作答被试。
方法六:连续相同作答分析(LongString Analysis)
Lengthy strings of invariant responses (i.e., the same option being selected repeatedly) may be indicative of low-quality data. 计算被试对于不同题目提供连续相同答案的数量,5555555, 345,6666666, 此处连续出现七个“5”, 七个“6”。
Response patterns in which respondents consistently respond with the same answer (e.g., “5”) can be identified via an approach recommended by Johnson (2005). This index, termed LongString is computed as the maximum number of consecutive items on a single page to which the respondent answered with the same response option. (Meade & Craig, 2012)。
问题是到底多少个连续作答才能算是不认真作答,可以删除呢?
答案是目前并没有明确的说法。
Given that more extreme responses are less likely, researchers have recommended screens on the basis of 6 to 14 invariant responses in a row depending on which response options are being endorsed (Costa & McCrae, 2008; Huang et al., 2012). The longstring screen is recommended when researchers are administering multidimensional surveys or questionnaires with a mixture of positively and negatively scored items (DeSimone et al., 2015)。
There are no established global cut scores in place for it. In keepingwith the approach of Huang et al. (2012) regarding a conservative cut score for response time, this paper will suggest baseline rule of thumb that individuals with a string of consistent responses equal or greater than half the length of the total scalebe considered as C/IE responders by this tech- nique (Curran, 2016).
个人倾向于支持Curran, 就是如果连续作答的数目超过了问卷长度的一半,肯定可以判断为无效数据。其它的就需要谨慎。如果你想要更严格一些,那么下面的可以用,8,或9作为cutoff score,下面是支持的文献。
Costa and McCrae (2008), participants who indicate consecutive strings of at least six “strongly disagrees,” nine “disagrees,” ten “neither agree nor disagrees,” fourteen “agrees,” or nine “strongly agrees” should be flagged. Huang et al. (2012) revised these estimates to seven, seven, twelve, ten, and eight, respectively. The cutoff of nine invariant responses was chosen because it reflects the median ofCosta andMcCrae’s(2008) analysis and is close to the mean (8.80) of Huang et al.’s(2012)analysis.
此外,这种方法可能在混合了反向计分或正面描述及反面描述题目的情况下才有效,比如工作倦怠和工作投入。
方法七:异常值分析(multivariate outlier analysis)
The Mahalanobis D statistic (Mahalanobis, 1936) is a multivariate version of outlier analysis that compares a respondent’s scores to the sample mean scores across all.Specifically, the Mahalanobis D is an estimate of the multivariate distance between a respon- dent’s scores on survey items and the sample mean scores on survey items. The underlying assumption of this technique is that extreme deviation from the normative response pattern may be indicative of insufficient effort (DeSimone et al., 2015). Recent evidence suggests that Mahalanobis distance can be effective at identifying inattentive responses (Ehlers et al., 2009).
方法八:问卷法:社会赞许和撒谎问卷 (social desirability & lie scale)
Examples include social desirability (e.g., Paulhus, 2002) and lie scales (e.g., MMPI-2 Lie scale), special scales designed to assess consistent responding (e.g., the MMPI-2 VRIN and TRIN scales)(Meade & Craig, 2012).
在这些问卷上得分较高的被试,值得关注。
方法九: 语义相近题目作答的一致性 (Semantic synonyms)
The semantic synonym technique is designed to identify respondents who indicate dissimilar responses to similar items. For example, “I enjoy my job” may be deemed semantically synonymous with “I like my current occupation.” Alternatively, survey designers may opt to repeat an item (or set of items) later in a survey (DeSimone et al., 2015).
Meade & Craig, 2012的建议
First,we encourage the use of identified responses but not the harsh wording in the instruction set used here.
其二,对于较长的问卷强烈建议纳入诈选题目,或者指定作答题目(e.g., “Respond with ‘strongly agree’ for this item”)—. 建议每50-100题目,插入一道指定作答题。We suggest incorporating approximately one such item in every 50–100 items up to a maximum of three. Respondents may become annoyed at such items if a large number appear (Meade & Craig, 2012).
其三,每一个基于网络的问卷,至少应该纳入一种甄别不认真作答的方法,建议增加一道简单的自我报告题目+作答时间。
We believe that every Internet-based survey research study would benefit from incorporating at least one careless response detection method. we suggest incorporating a simple self-report measure (i.e., “In your honest opinion, should we use your data?”), coupled with a cursory look at response time for outliers. If only post hoc methods are available, then inspection of response time and computation of the Even-Odd Consistency measure are suggested as minimums (Meade & Craig, 2012).
对于一些想要更严格的数据筛选,可以考虑加入指定作答题目+ 三种不同的统计方法 (比如奇数偶数一致性)(Meade & Craig, 2012)
DeSimone的建议对于研究设计的启示:
一些在我们本科学习到的问卷设计方法依然有用。
比如, the use of both positively and negatively worded items is required for the assessment (and potential dissuasion) of acquiescent responding (Anastasi, 1988; Ray, 1983).
Also, the use of longer scales is associated with higher values for coefficient alpha (Cortina, 1993; Cronbach, 1951; Schmitt, 1996) and higher validities (Credé, Harms, Niehorster & Gaya-Valentine, 2012).

来源:(DeSimone et al., 2015)
关于数据筛选(curran)的建议
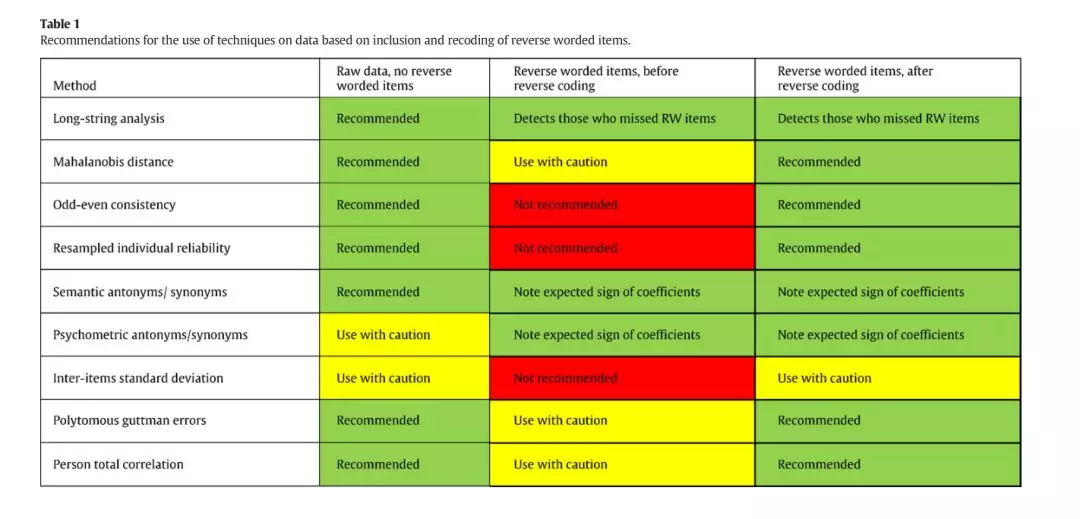
来源:(Curran, 2016)

问卷设计的建议小结
1. 控制问卷长度。如果有100-150 到题目,插入1-2 题指定作答题。太多会干扰作答,甚至会惹怒被试。
2. 最后插入一道自我报告的是否认真作答题目。
3. 问卷纳入积极和消极的变量,比如离职意愿与组织承诺。
4. 如果去企业收集,可以召集被试到办公室完成问卷,减少无关干扰。
5. 记录作答时间(电子问卷即可)。
6. 提供一定的报酬(incentive, 可以是金钱,也或者是一场关于研究结果的报告)
7. 采用1-2中统计方法筛选数据。比较容易实现的:作答时间,被试平均每个题目作答小于2秒钟,值得关注;此外,连续相同答案个数超过问卷长度的一半,很大可能是随机填写。
8. 如果进行了数据筛选,比较筛选前后分析结果,并在论文进行报告。
数据筛选在R中的实现
本文介绍的所有利用统计的比如response time, longstring, 异常值都可以在R包里实现。

#careless data screen#using package "careless#install.packages#install.packages("careless")library(careless)library(foreign)#A data frame with 200 observations (rows) and 50 variables (columns).方法五:奇数偶数作答一致性
#1.1 evenodd_within-person correlation betwen even adn odd subscales#evenodd(x, factors, diag = FALSE)careless_eo <- evenodd(careless_dataset, rep(5,10))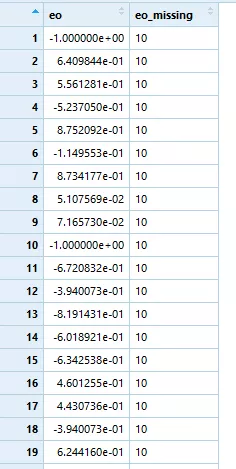
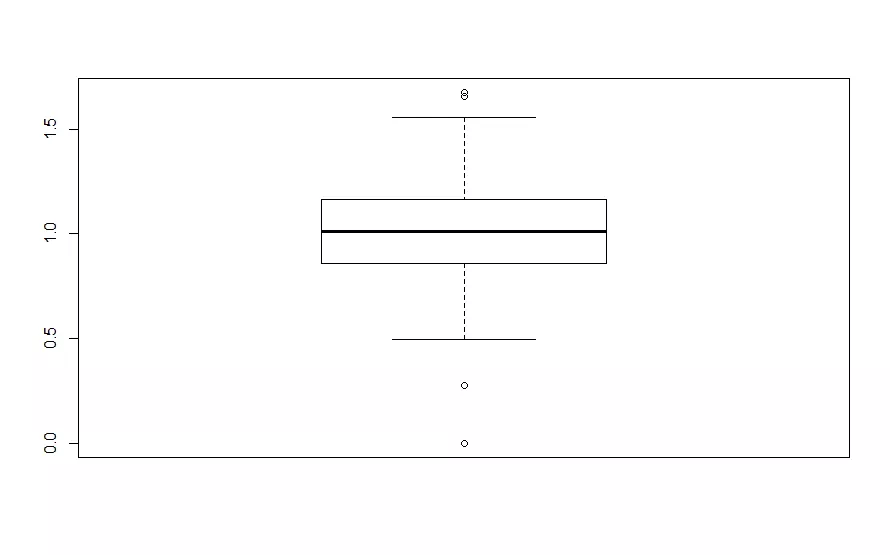
#1.2 Calculates the intra-individual response variability (IRV)irv_total <- irv(careless_dataset)irv_split <- irv(careless_dataset, split = TRUE, num.split = 4)boxplot(irv_split$irv4) #produce a boxplot of the IRV for the fourth quarter
方法六:连续作答
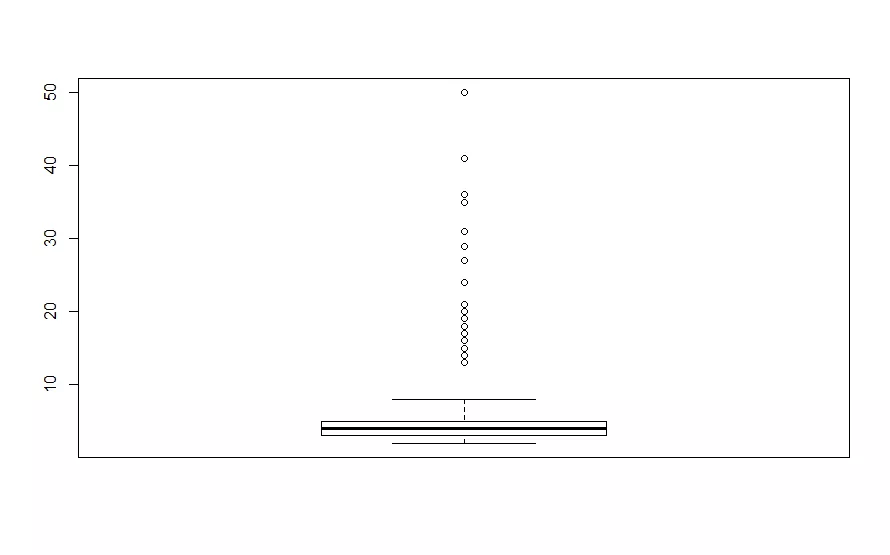
#1.3 longstring analysis#function longstring(x, avg = FALSE)careless_long <- longstring(careless_dataset, avg = FALSE)careless_avg <- longstring(careless_dataset, avg = TRUE)boxplot(careless_avg$longstr) #produce a boxplot of the longstring index方法七:异常值
#1.4 mahad#Find and graph Mahalanobis Distance (D) and flag potential outliers.mahad_raw <- mahad(data) #only the distances themselvesmahad_flags <- mahad(careless_dataset, flag = TRUE) #additionally flag outliers

注:其实这个package不是很好用,尤其是tutorial不是很清楚,如果大家有更好的方法欢迎分享~
最后的最后:
可以说,以上这些方法都似乎不是完美的,这也是问卷研究的窘境,但是利用几种方法尽可能做到严瑾,也聊胜于无吧。如果您有更好的方法也欢迎分享。
本期到此结束,如果觉得有用,请点文末“再看”~作者码字不易……
本文作者:李培凯
本期排版:杨伟文
关于作者
往期精选 Mplus:结构方程模型 MPlus 基础篇: CFA,EFA,中介,调节调节模型 交叉滞后中介模型Mplus的应用 Latent Growth Modeling(潜增长模型) Latent Transition Analysis(潜在群组转变): Mplus分析详解 顶级英文期刊文章的潜在剖面分析如何用Mplus 来实现 Mplus:多水平数据中介模型检验 重复测量纵向追踪数据——时间序列分析 R&Mplus 的应用 多水平数据分析:R、Mplus和 HLM 应用对比 Mplus中介调节模型简单效应分析及做图 元分析 元分析高阶篇:中介模型分析—R metaSEM的运用 R语言实现元分析-随机对照干预研究 元分析所用R全部代码及详细解释 R语言:贝叶斯因子方差分析--理论与实操 写作与发表 如何进行博士/研究选题和经营你的研究生涯? 论文的Title或是我们文章被拒的开始 How to Publish and Review How to be a good reviewer 英文文章摘要、引言怎么写? AMJ最佳审稿人告诉你 如何在顶级英文刊物上发表论文 高级检索,文献管理,两秒完成英文参考文献核对  75 0 0
75 0 0- 关注作者
- 私信作者
- 转 发
- 加入收藏


- 热门文章
-
 Praat英文教程——Speech Signal P...2019-12-19
Praat中文教程-熊子瑜老师2004版《Pr...2019-12-19
Praat英文教程——Speech Signal P...2019-12-19
Praat中文教程-熊子瑜老师2004版《Pr...2019-12-19 黄丽娜《助听器问卷的跨文化翻译和适用...2020-02-04
罗润芬等《加速康复外科护理在小儿人工...2020-02-04
黄丽娜《助听器问卷的跨文化翻译和适用...2020-02-04
罗润芬等《加速康复外科护理在小儿人工...2020-02-04
- 最新文章
-
 AN INTRODUCTION...2020-05-06
AN INTRODUCTION...2020-05-06 R语言和Jspsych编写本地和在...2020-02-16
R语言和Jspsych编写本地和在...2020-02-16 【科普短文】P300事件相关电位...2020-02-09
【科普短文】P300事件相关电位...2020-02-09
- 技术支持
-
管理员微信
 电话:010-82185409邮箱:service@phonetics.com.cn
电话:010-82185409邮箱:service@phonetics.com.cn京ICP备18027836号-11 京公网安备 11010802032611号