

-
EEGLAB脑电数据预处理指导手册2019-12-28本篇转载自微信公众号:BrainTechnology,推送的是一位酷爱分享脑科学的网友喵喵姐姐撰写的《EEGLAB脑电数据预处理指导手册》,图文并茂,浅显易懂,敬请品读!
EEGLAB脑电数据预处理指导手册
这是来自一位酷爱分享脑科学的同行喵喵姐姐的文章。这是她的公众号二维码:

文章开始:


解读:eeglab是基于MATLAB的一个工具包,一般加载的时候都从添加子文件夹导入。在添加多个工具包时,记得只保留必要的工具包,避免兼容报错的问题。
一、导入数据
步骤1:File - Import data - 不同的数据格式不同的导入方法
解读:其中BP设备和ANT设备的数据,都是从.vhdr中导入。
步骤2:File - Load exiting dataset - eeglab_data.set
解读:若是导入eeglab保存的数据,则直接按照步骤2导入即可。
来源:AffectiveNeuroscience

二、定位电极(时间)
步骤:Plot - Channel data(scroll) - settings - time range to display -setting - number of channels to display value(调整幅度)
解读:可以在数据分析之前,浏览一下原始数据,自己对数据的好坏有一个评估。

三、定位电极(空间)
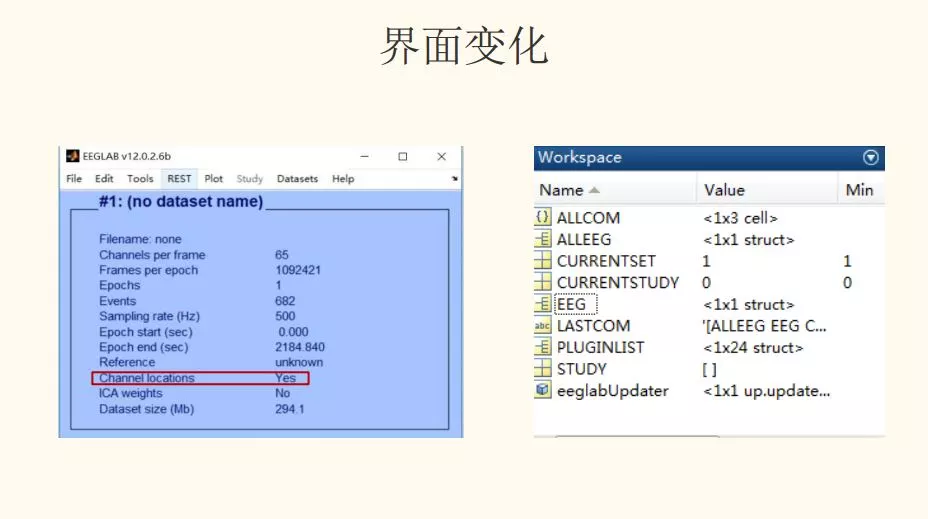
步骤:Edit - Channel locations - read locations ( look up locs) - eeglab_chan64.locs(plot 2D)
解读:在数据分析之前,查看电极点的分布图,方便后期进行使用插值法进行坏点替换。

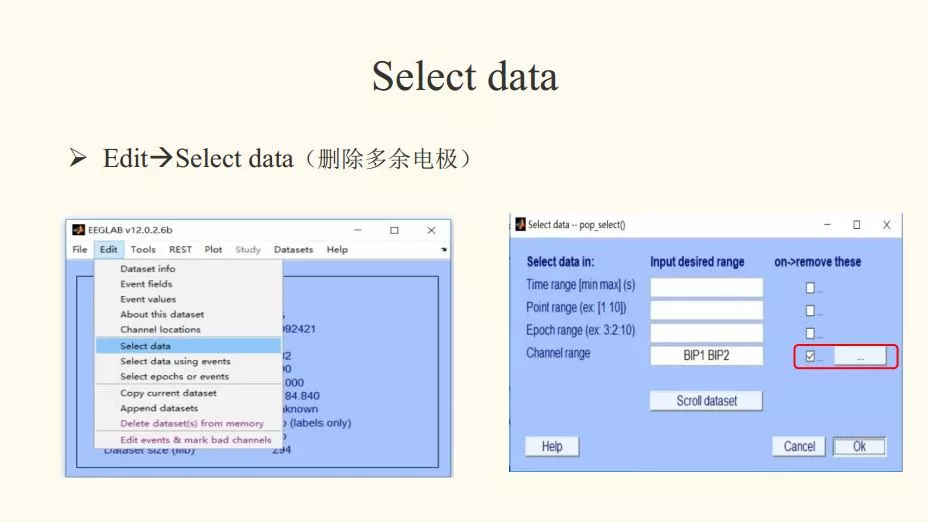
四、删除无用电极
步骤:Edit - Select data - 点上√,即删除选取的电极;不点√,则是删除剩余的电极。
解读:删除记录多余的电极,只选取自己需要的电极。

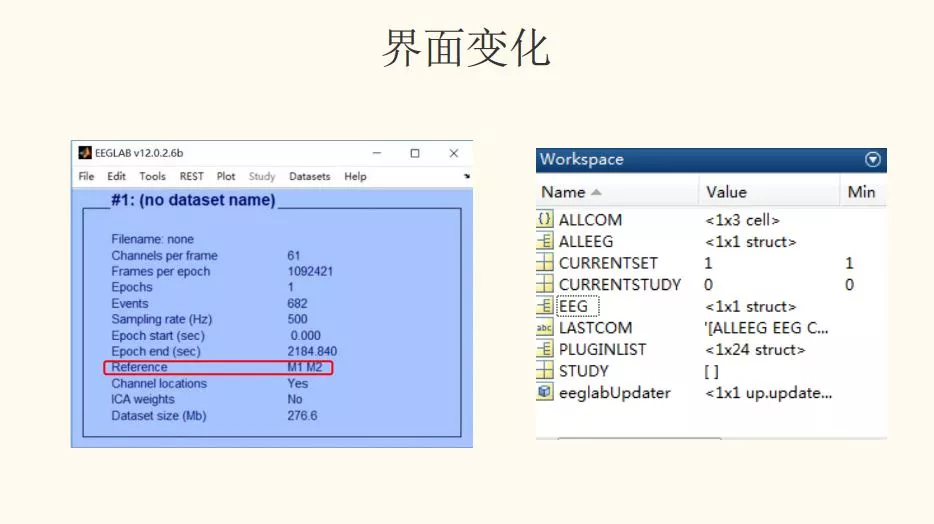
四、重参考
步骤1:Edit - Re-reference - re-reference data to channel(s) - 电极点 M1 M2 (TP9 TP10) (双侧乳突)
步骤2:Edit - Re-reference - compute average reference(全脑平均)
步骤3:使用 rest-reference 插件(零参考)
解读:重参考的方法常用的有双侧乳突、全脑平均、零参考,具体选取那种方法根据以往的参考文献和自己的需要来进行选择。
重参考也是一种空间滤波,主要是通过另外一个角度来看问题。所以不同的在线参考其实对于离线参考没有太大影响。

五、滤波
步骤1:Tools - Filter the data - basic FIR filter - (1 Hz high pass filter first) - Overwrite it in memory(根据需要获取目标频段)
步骤2:Tools - Filter the data - Basic FIR filter - (30 Hz low pass filter second) - Overwrite it in memory
解读:高通滤波,是指高频信号能正常通过,而低于设定临界值的低频信号则被阻隔、减弱。因而是进行1Hz的高通滤波,而选择的时候,1Hz是频率通过的下限。
低通滤波,是指低频信号能正常通过,而超过设定临界值的高频信号则被阻隔、减弱。因而是进行30Hz的低通滤波,而选择的时候,30Hz是频率通过的上限。
早期的eeglab版本,不能够同时滤波,容易卡死;最新版本的eeglab是可以同时进行空间滤波的。
若是后期要做时频分析,可以滤波的范围选择更宽一点,选择0.1-100。若是只进行传统的ERP分析,可以选择1-30左右。
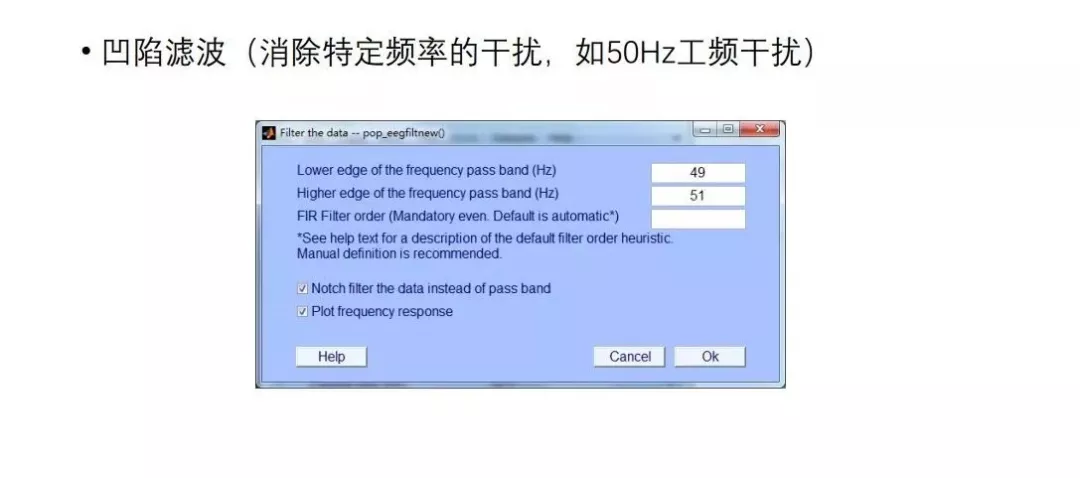
此外,若是进行0.1-100Hz的滤波,为了消除市电的干扰,可以进行50Hz的凹陷滤波。

六、分段和基线矫正
步骤:Tools - Extract epochs(分段 marker 全选)- Automatic baseline correction
解读:分段的步骤,可以在去除眼电之前,也可以在去除眼电之后。其实最好是在去除眼电之后,因为连续的数据在跑ICA时更好,只是数据量比较大,跑的速度比较慢。
但是若是实验设计当中有出声、身体动,造成伪迹较多,数据杂乱,可以先分段,只是可以在分段的时候,尽量分段长一点。

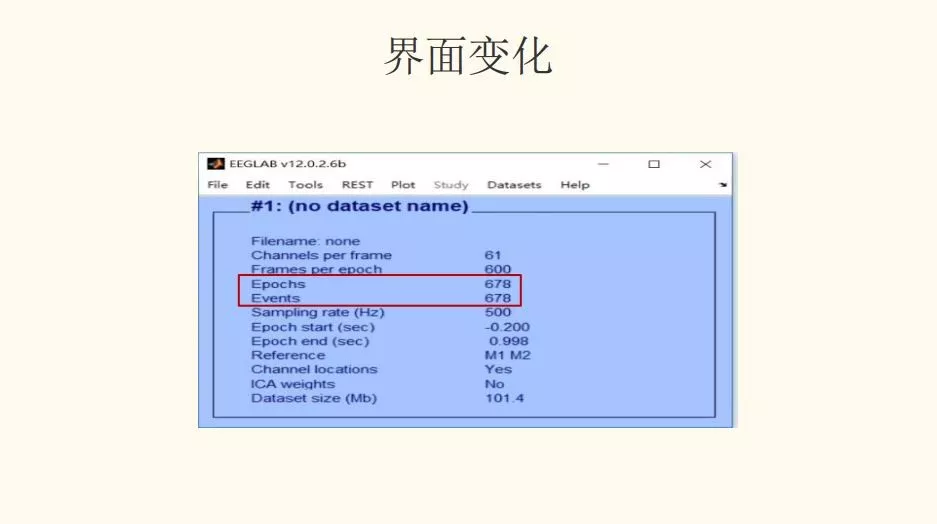
七、伪迹去除
步骤1:Plot - Channel data(scroll)(删除坏的trial)- 差值坏导(代码)
步骤2:File - Save as - 保存文件
解读:伪迹去除是去除眼电之外的其他杂乱的伪迹,使得在 Run ICA之前的数据比较干净,容易找到眼电成分。

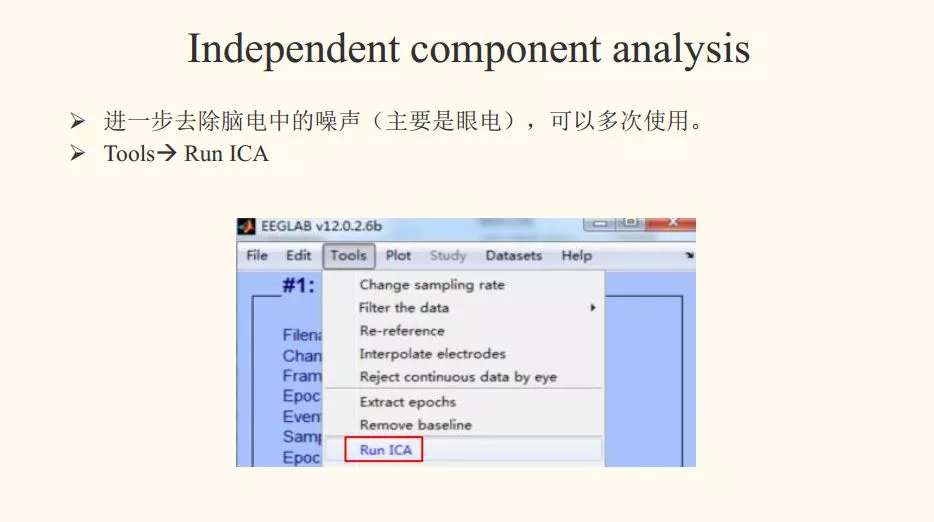
八、Run ICA
步骤:Tools - Run ICA - 'extended',1'pca',30 - OK
解读:Run ICA 的时候,可以写30个,也可以写60个主成分。去除的时候,需要去除自己最肯定的成分,一般都是去除眼电成分。


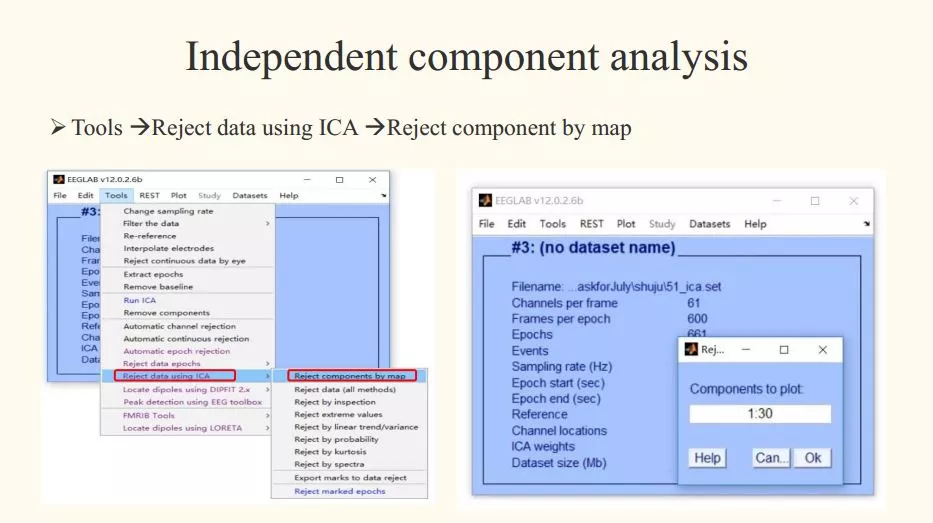
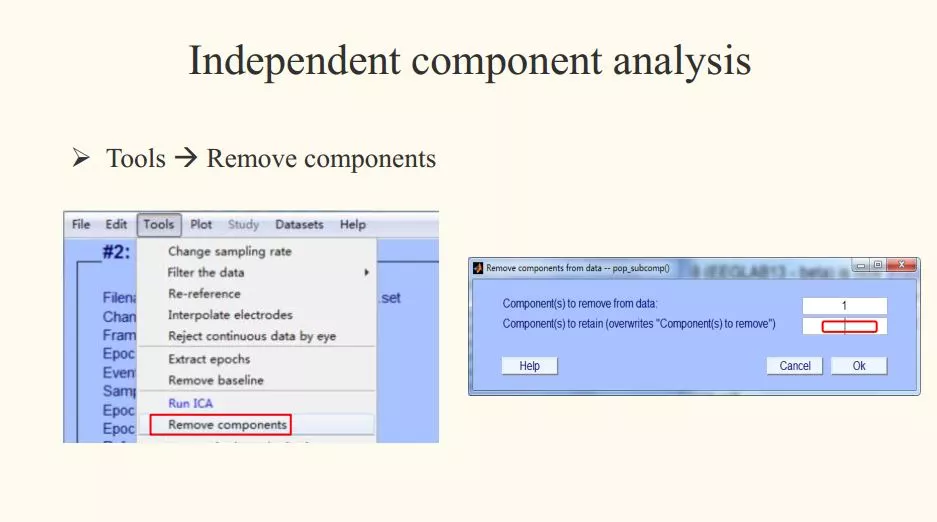
九、眼电去除
步骤1:Tools - Reject data using ICA - Reject component by map
步骤2:Select each IC and observe
步骤3:Tools - remove components - 填写删除电极的数字 - OK
解读:眼电判断的时候,除了看地形图,也可以看频率分布图、每个成分的波形图,以及矫正之后的脑电图是否有差异,进行综合的评估。
只有自己很确定的伪迹主成分才删除,不然可能会删除自己想要的成分。
若是出来的成分,没有出现明显的伪迹成分,可以多跑几次ICA;或者不分段重新跑一次;再或者再看看原始数据,删除杂乱的成分,重新再跑一次。
这是一步是很需要经验的步骤,若是前期自己把握不准,可以让有经验的人帮忙看看。
通过Adjust插件,也可以进行一个简单的伪迹成分的评估,不过最终的确定还是需要自己来进行评估。
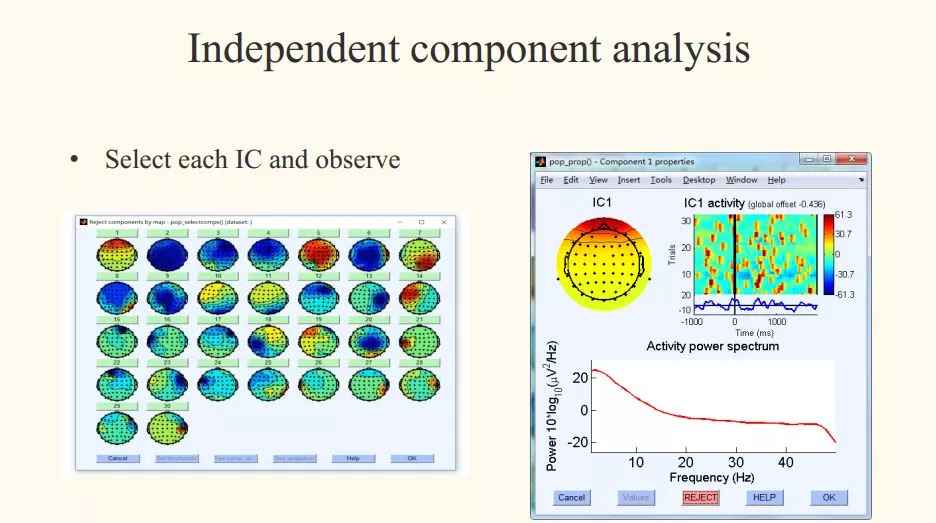
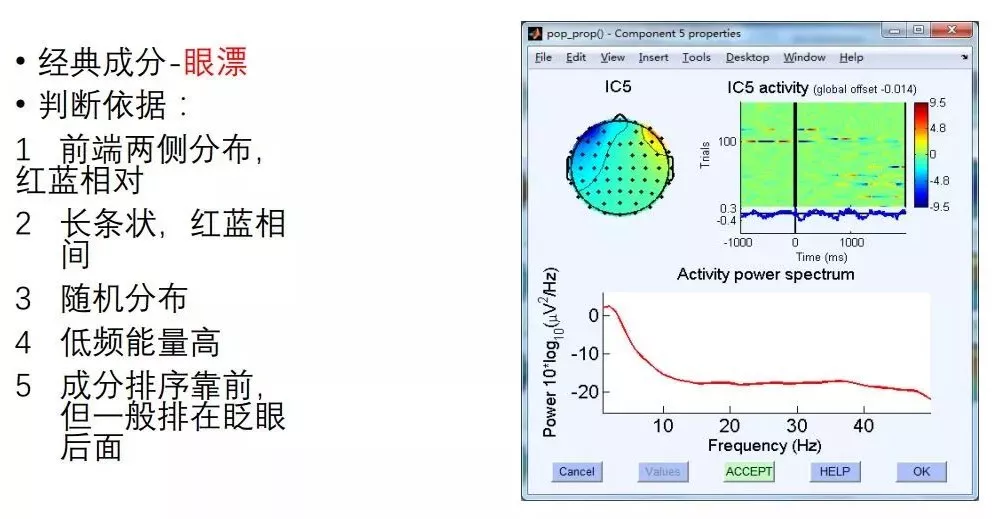
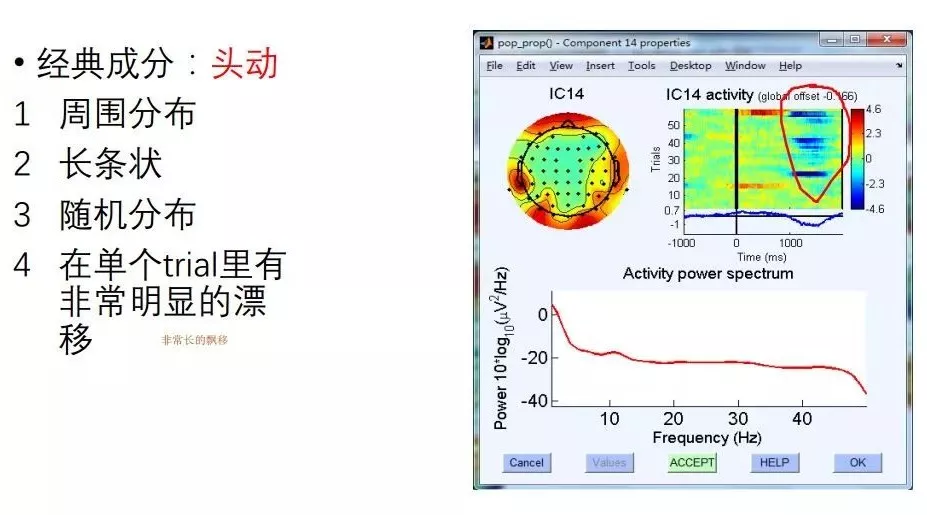
眼电去除的标准
来源:彭微微老师




十、预处理的批处理
步骤:eeg.history - 出现之前处理的代码 - 进行每个被试的批处理 - 然后处理完之后再手动去除眼电成分 - 保存为处理干净的脑电信号 - 进行下一步的分析
解读:脑电数据的预处理是为了提高信噪比,去除噪音,得到比较干净的数据。从而进行下一步的分析。

后续整理工作

来源:彭微微老师
解读:保存数据并整理,方便后期分析;保存图片,方便自己对数据的把握和可视化的呈现。
283 0 0- 关注作者
- 私信作者
- 转 发
- 加入收藏

- 热门文章
-
 Praat英文教程——Speech Signal P...2019-12-19
Praat中文教程-熊子瑜老师2004版《Pr...2019-12-19
Praat英文教程——Speech Signal P...2019-12-19
Praat中文教程-熊子瑜老师2004版《Pr...2019-12-19 罗润芬等《加速康复外科护理在小儿人工...2020-02-04
黄丽娜《助听器问卷的跨文化翻译和适用...2020-02-04
罗润芬等《加速康复外科护理在小儿人工...2020-02-04
黄丽娜《助听器问卷的跨文化翻译和适用...2020-02-04
- 最新文章
-
 AN INTRODUCTION...2020-05-06
AN INTRODUCTION...2020-05-06 R语言和Jspsych编写本地和在...2020-02-16
R语言和Jspsych编写本地和在...2020-02-16 【科普短文】P300事件相关电位...2020-02-09
【科普短文】P300事件相关电位...2020-02-09
- 技术支持
-
管理员微信
 电话:010-82185409邮箱:service@phonetics.com.cn
电话:010-82185409邮箱:service@phonetics.com.cn京ICP备18027836号-11 京公网安备 11010802032611号