

1550 阅读 2020-02-10 18:41:36 上传
SPEECHREADING OF WORDS AND SENTENCES BY NORMALLY HEARING AND HEARING IMPAIRED CHINESE SUBJECTS: THE ENHANCEMENT EFFECTS OF COMPOUND SPEECH PATTERNS
Xinghui HU, Adrian FOURCIN, Andrew FAULKNER and Jianing WEI
Introduction
Speech perception requires a receiver to make decisions both about trends and also about the language patterns of a speaker. Hearing people use the speaker’s speech signal as the direct sensory evidence. In the special case of visual speech perception, otherwise known as speechreading, this sensory evidence is derived from the visible articulation movements of speech. Unfortunately, many important articulation movements are invisible. On the segmental level, some articulation positions are difficult or impossible to distinguish. Even for those sounds that are visible, few have unique visual cues. At the suprasegmental level, the basic speech elements intonation and lexical tone which are mainly conveyed by the vibrating frequencies of the larynx, are totally missing in visible facial gestures. Therefore, a successful speechreader has to compensate for the resulting shortage of sensory data by taking maximal advantage of prior knowledge of language structure and of the linguistic and situational context. This process is demanding, however, and even the most competent speechreaders have to accept a substantial probability of error.
It is a common observation that the addition of a small amount of auditory input to the visual stimulus of speechreading enhances speech perception, often dramatically. The enhancement effect is found in profoundly deaf subjects, for whom the auditory evidence available from the acoustic speech signal is limited by cochlear pathology (Erber, 1972, 1979). It is also found in normally hearing people when the speech signal is low-pass or band-pass filtered (Breeuwer & Plomp, 1984) and when selected formant information is made available (Breeuwer & Plomp, 1985, 1986).
It has been shown that the enhancement effect can occur when the only auditory input is the patterns of unsmoothed variations of voice fundamental frequency (Fx) over time. In 1981, Rosen, Fourcin and Moore reported marked improvements in the transmission rate of connected discourse when normally hearing subjects were allowed to hear Fx contours in addition to watching the speaker’s face. The conclusion that auditorily presented Fx provides enhancement of speechreading is supported by the studies using both normally hearing subjects (Breeuwer & Plomp, 1986; Grant et al., 1985; Risberg and Lubker, 1978; Boothroyd et. al, 1988; Ebehard et al, 1990) and hearing-impaired subjects (Grant, 1987; Rosen et al., 1979; Faulkner et al., 1989, 1990, 1992).
Boothroyd et al. (1988) reported that the enhancement effect of Fx, on average, amounts to a 40% increase of the correct percentage of words recognized in topic known sentences when the electroglottograph (EGG) signal was used as an auditory supplement to speechreading; and in normally hearing subjects, the existence of the Fx enhancement effect is independent of speechreading competence, however, the magnitude of the effect, expressed as percent reduction of error, tends to increase with increasing speechreading competence.
Chinese which these findings are of especial interest for is a tone language. The tonal contrasts are meaningful and play a very important role in communication (Zhang et al, 1984). Lexical tones are mainly to be perceptually distinguished from each other by the patterns of voice fundamental frequency. Some experiments showed that the auditory supplement with voice fundamental information could enhance speechreading by Chinese speakers (Ching, 1986; Wei et al. 1991; Wei et al. 1992). Speech pattern element hearing aids are believed to be able to give substantial information to tone language users (Fourcin, 1986, 1990).
Another missing speech feature in facial gestures is frication. Frication information is largely present in the frequency range above 2000Hz and it is generally inaccessible to profoundly deaf people’s residual hearing even when speech intensity is compensated for according to their hearing losses. The auditory presentation of frication information by the way of low-frequency range noise signal has been shown to give benefits to hearing-impaired people (Faulkner, 1992; Wei, 1992) when they are speechreading.
The use of controlled combination of these speech features makes it possible to explore the links between the sensory processing of speech elements and language receptive ability. Compound speech pattern elements(Faulkner et al, 1990; Fourcin, 1986, 1990) -- voice fundamental frequency, frication, and speech amplitude envelope, are presented in real-time by a wearable digital instrument SiVoIII (Walliker and Howard, 1990, Wei et al. 1990). Voice fundamental frequency is detected by a neural network system (Howard, 1990; Wei et al., 1993). Speech frication detection is implemented by using a spectral-balance method. A sinusoidal waveform of the voice fundamental frequency for voiced segment and a low-frequency band random noise signal for voiceless segment are generated by look-up table method. Generated signal is multiplied by the square root of the speech amplitude envelope, and the ratio of the amplitude between voiced segment and voiceless segment is reduced.
Two initial experiments will be described. Both involved measurement of speech perception by speechreading with and without the addition of an auditory presentation of compound speech pattern elements. In the first experiment, ten normally hearing subjects and one hearing-impaired person were asked to recognize the isolated words by speechreading using a counterbalanced design. Two normally hearing people were asked to speechread the words with the addition of three different combinations of the voice fundamental frequency, frication and amplitude envelope. Three profoundly hearing-impaired subjects were required to speechread the word by seeing the face alone, with the auditory supplement of amplified speech, and with the auditory addition of compound speech pattern element signal from a SiVoIII hearing aid. In the second experiment, nine normally hearing persons and one hearing-impaired subject were asked to speechread the sentences visually alone and with the supplement of the compound speech pattern element signals.
The main goals of the experiments described were: 1. to assess the nature and measure the magnitude of enhancement effect of the compound speech pattern elements, and 2. to compare the effect of compound speech pattern element signal with that of amplified speech to profoundly hearing-impaired Chinese people.
Method
Methodological Considerations In order to assess speechreading performance, many recent studies have relied on the method of continuous discourse tracking (CDT, De Filippo and Scott, 1978). In CDT, an experimenter reads from a book and the subject is required to repeat verbatim what was said. If neccessary, the experimenter repeats sentence fragments several times until the subject can repeat the sentence correctly. The performance measure is words correct per minute (wpm). Although the CDT task does mimic some of the interactive and cognitive, linguistic aspects of natural communication, many uncontrolled variables significantly affect tracking rates, and thus the technique has pitfalls when used for evaluating sensory aids, as has been noted in the past (Matthies and Carney, 1988; Tye-Murray and Tyler, 1988). An alternative method used in several researches (Eberhard and Bernstein, 1990; Hanin et al., 1988; Boothroyd et al., 1988) is to present prerecorded isolated sentences. For the current study, a sentence corpus was developed and recorded on SVHS video tapes for the purpose of achieving the desired stimulus control.
Test Material
Forty words, twenty sentences and two short passages were developed and recorded for training purpose.
240 Chinese words were selected from the most frequently used 1,000 words in Chinese newspapers, books, and magazines (Chinese Vocabulary Survey, 1988). A word list consists of 15 monosyllabic words, 40 disyllabic words and 15 trisyllabic words. The occurrence of the four lexical tones in each word list is balanced according to their relative frequencies(Zhang, 1984).
A Chinese version of BKB sentences has been used for the sentence speechreading tests. These sentences are meaningful and easily understood and close to daily life. There are 10 sentence lists and 16 sentences in each list. All the sentences have length from seven to nine Chinese characters and four to six words. Three key words in each sentences are to be scored.
A female native Chinese speaker from Beijing, China, spoke the word and sentence lists. Each list was read twice and the words or sentences in the list came in different order each time. The speaker was recorded by a SONY video camera to a SVHS Hi-Fi NiCam recorder with speech and Laryngograph signal recorded to the two audio channels. A computer monitor was presented in front of the speaker about two meters away and just below the video camera. Reading materials were displayed on the screen and the procedure was controlled by a PC with a Laryngograph PCLX card to play out a beep sound before each stimulus. The time interval was 10 seconds between successive words and 20 seconds between successive sentences.
The view was frontal, from the top of the head to the shoulder. Two lights were used. They were placed symmetrically at approximately 25 degrees from the azimuth in front of the talker. Recordings were made in a sound proof chamber.
The recorded word and sentence lists are used to all the subjects participating in the experiments. For the profoundly hearing-impaired subjects, the SiVoIII hearing aid was individually programmed to give optimal audible levels.
Subjects
Twelve normally hearing college students and four profoundly hearing impaired people participated in the study. All had normal or corrected-to-normal visions. None of the normal hearing subjects were experienced speechreaders. All the subjects were paid for their experimental work.
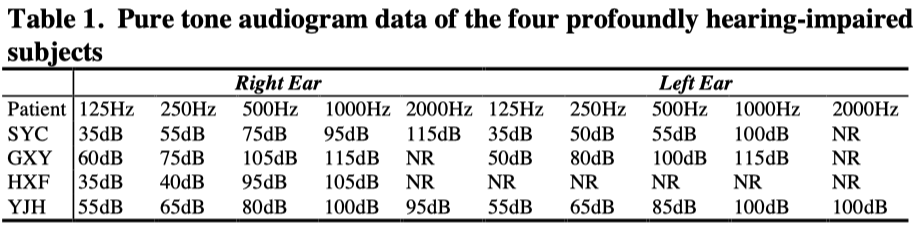
One in the group of hearing-impaired people, YJH, 25 year old, became profoundly deaf before six years of age, and the cause of hearing loss was the use of neomycin and kanamycin. She has had a stable hearing loss for nearly nineteen years. She started to wear a pair of Oticon hearing-aids in her daily life about four years ago. Her speech was obviously deficit and her Chinese tone production ability is poor. A informal tone perception test showed that she could not tell the four tones apart from each other. According to her, the main acoustic cue in tone perception she used was amplitude envelope information. However, her whole speech was intelligible and she had a good lip-reading capacity and was able to communicate with hearing people. She has been a teacher in a deaf school for more than three years.
All the other three hearing-impaired subjects had nearly normal speech production. None of them is a constant hearing-aid user since they do not find conventional hearing aids suitable. GXY was found to have acquired an adventitious hearing loss at the age of 16. She is about 35 year old now. SYC is 42 year old , and has had a profound hearing loss for more than 24 years. The cause is still unknown. HXF is a housewife now and she used to work for a fabric factory. She suddenly could not hear three years ago and the cause of hearing loss is unknown. She can hear whole speech occasionally for a very short time. She has no hearing aids. All of the hearing-impaired subjects’ conversations with other people are mainly dependent on speechreading.
General Procedure
Each subject was given about 25 minutes to gain speechreading experience with and without the addition of the compound speech pattern element signals. Before doing word and sentence recognition tasks, they spent about 35 minutes taking part in tests on the recognition of Chinese initial consonants.
The tests were arranged such that speechreading only and speechreading with auditory supplement came alternately in order to balance the learning effects. The subjects were allowed to have a five- minute break after two lists of words / sentences. It takes about 12 minutes to do a sentence list and 7 minute to do a sentence list.
The subjects were required to write down their answers on the answer sheet within the given time duration, 10 seconds for word tests and 20 seconds for sentence tests. They were encouraged to write down whatever they perceived and not to leave the answer sheet blank. Every subject took one test to get familiar with the running speed before the normal tests.
Data Analysis All data analyses were performed using SPSS 6.1 for Windows. For the isolated word recognition experiment, a two-factor analysis of variance was used. The dependent variable was the number of words correct in a list. The factors were sound and word list. Both factors were considered fixed. For the isolated sentence recognition test, a two-way factor analysis of variance was used. The dependent variable was the number of words recognized in a sentence list. The factors in the experimental design included sound, sentence list.
Experiment I: Isolated Word Recognition
Word recognition results by normal hearing subjects with and without the supplement of compound speech pattern element signals A(Fx+Nx) to speechreading
A special consideration was taken into account when the subjects’ word recognition answers were scored. Chinese is a tonal language and there are many words in Chinese having identical syllabic structure but corresponding to different tone patterns. When scoring responses to the speechreading alone mode of testing, an answer was taken to be correct if its syllable structure was identical with that of its stimulus. Tone correctness was similarly considered when the responses to the aided speechreading mode of testing were scored.
Scores
Table 2 shows eleven subjects’ numbers of words correct in each list for speechreading alone and for speechreading with the addition of SiVoIII signal. In Table 2 the percentage correct across all the test lists are given for the subjects with two test conditions. It will be seen that the probability of word recognition was between 8.8% and 42.5% by speechreading alone, but rose to between 43.8% and 77.5% with the addition of SiVoIII signals, giving a enhancement effect of between 29.2% and 41.2%. All the subjects showed substantial increase in their word recognition performance. The average enhancement effect across all the subjects is 35.8%.
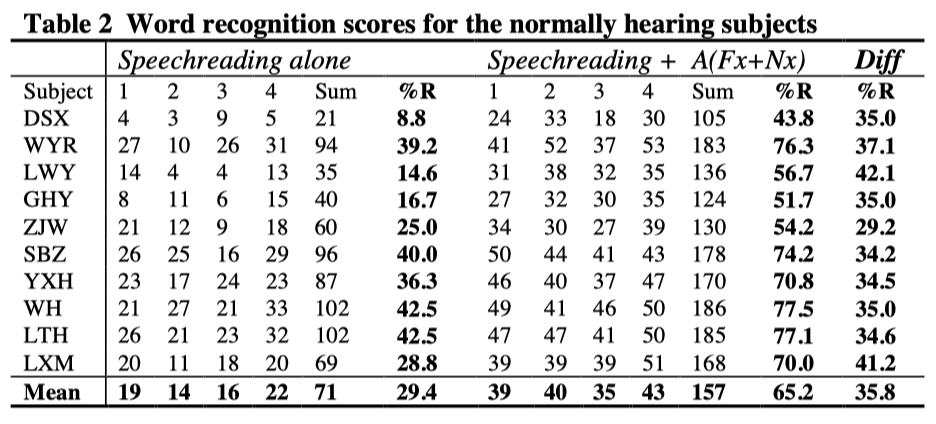
Comparison of sound conditions and word lists The first principal question addressed in this study was whether performance was superior under aided condition. This question was examined initially in terms of the contrast comparing aided and unaided speechreading performance. This contrast was highly significant [F(1, 10386) = 1017, p < 0.0005].
The second question addressed in this experiment was whether the four word lists were of equal difficulty levels for all the subjects. The contrast among the four lists was highly significant [F(3, 234) = 21.95, p < 0.0005]. However, the interaction between the sound condition and the word list was not significant [F(3, 37) = 1.77, p = 0.174]. This means that the different word lists did not introduce significant difference in enhancement effect in the population.
Subject differences
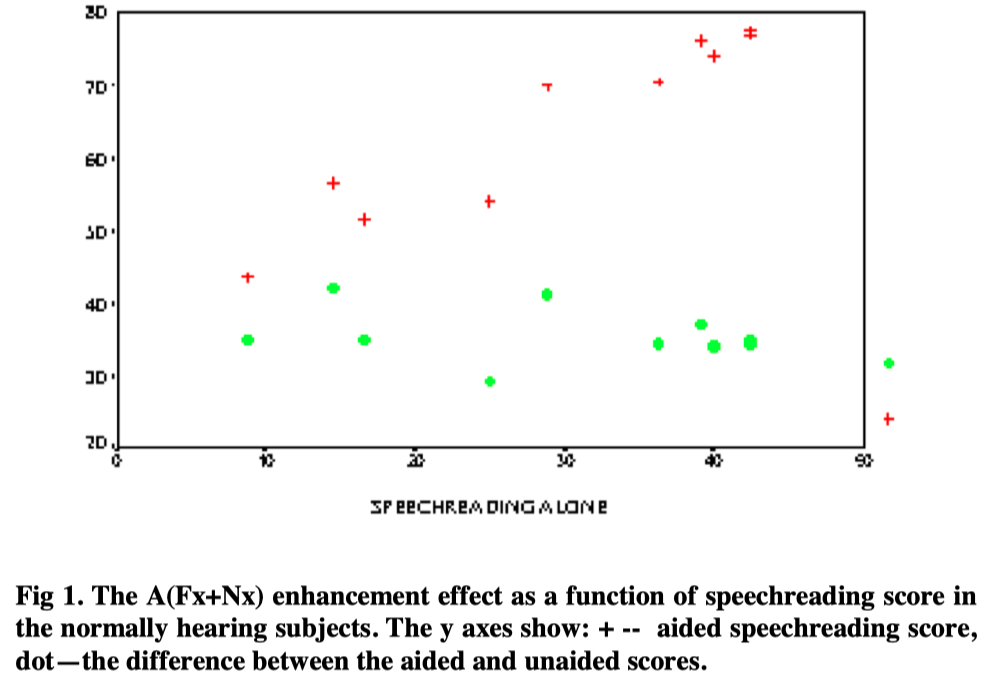
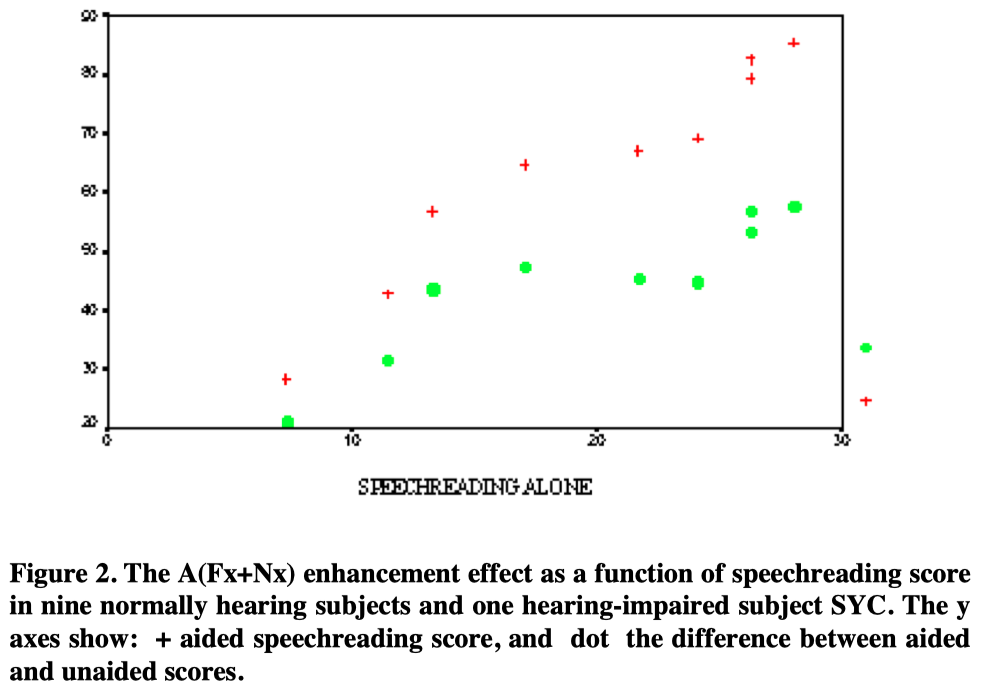
Individual scores for the four word lists were averaged under sound conditions. In Figure 1 the supplemented scores and differences between aided and unaided scores are plotted as functions of the unsupplemented scores.
It will be seen that the enhancement effect was present for all subjects, regardless of unaided speechreading scores, even though the latter covered a range from 8.8% to 42.5%. When expressed as a difference of percentage score, the enhancement effect averaged 35.8 percentage points and is irrelevant to the subject’s speechreading ability(r=-0.192, p=0.59), but the aided performance is highly related to the unaided score (r=0.957, p<0.0005).
Contribution of different speech pattern elements (Fx, Nx, and Amplitude) Two additional normally hearing subjects did the isolated word recognition test under four different conditions of auditory supplement. These are: 1. speechreading alone; 2. speechreading plus amplitude envelope and voice fundamental frequency—AFx (SiVoII); 3. speechreading plus amplitude envelope, voice fundamental frequency, and friction—A(Fx+Nx) (SiVoIII); and 4. speechreading plus amplitude envelope, friction, and voicing—A(Fconst+Nx). In the last situation, a constant frequency sine wave was used to indicate voicing information. Random order was assigned to avoid learning effects.
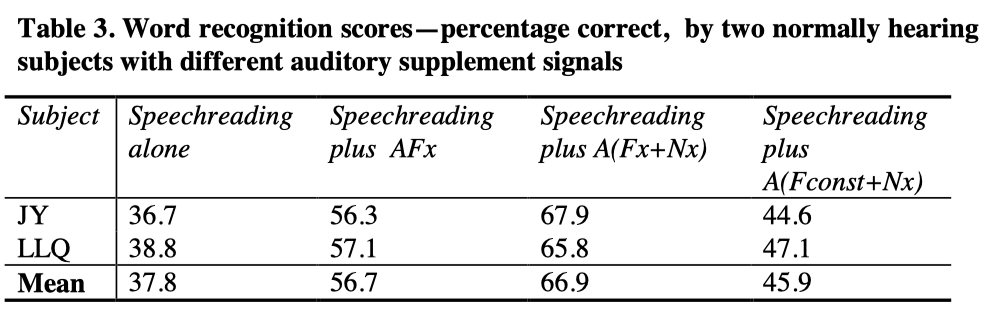
The average magnitude of enhancement effect of AFx as auditory supplement to speechreading, expressed as the increased percentage of correctly recognized words, is 19.9%. When noise was added to indicate friction, the magnitude of enhancement effect increased to an average of 29.1%.
Word recognition by the profoundly hearing impaired subjects
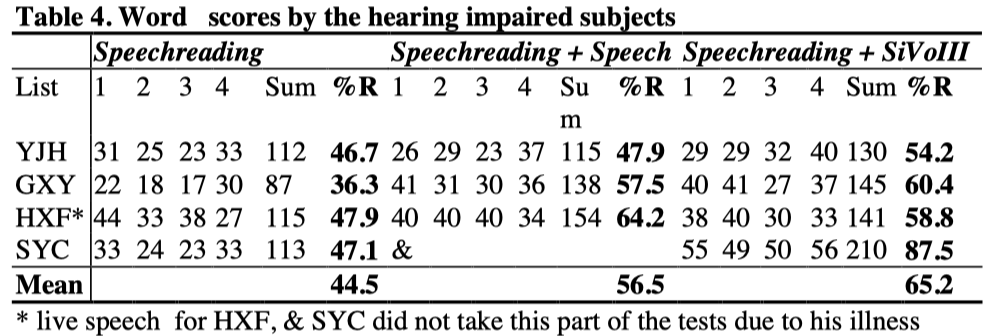
Three profoundly hearing subjects did the isolated word recognition tests. The subject YJH had her own pair of Audis conventional hearing aids. She used her own hearing aids in the speechreading plus amplified speech tests. The other two subjects did not have their own conventional hearing aids and the pass through mode in a SiVoIII hearing aid was used. Table 4 shows the profoundly deaf subjects’ scores of the word recognition tests.
It will be seen from the Table 4 that all the four subjects obtained benefits from the auditory supplements. For the subjects YJH and GXY, they obtained more benefits from the SiVoIII than from amplified speech, but the differences are small (6.3% for YJH, 2.9% for GXY). The subject HXF did better with amplified speech that with SiVoIII and the difference is small too (5.4%). SYC obtained 40.4% increasing in words correctly recognized and this increase is slightly larger than the average enhancement effect from the normally hearing subjects.
Experiment II: Isolated sentence recognition
160 isolated sentences were grouped into ten lists and each list had 16 sentences. Each sentence list was tested on the same subject by speechreading only and with the addition of compound speech pattern element signals while different sentence orders were used in these two conditions. The time interval between two tests was at least two days. The subjects were asked to write their answers on the answer sheet. The results were scored as number of words correct in the list and number of sentences correct.
Speechreading of isolated sentences by normally hearing subjects
Scores
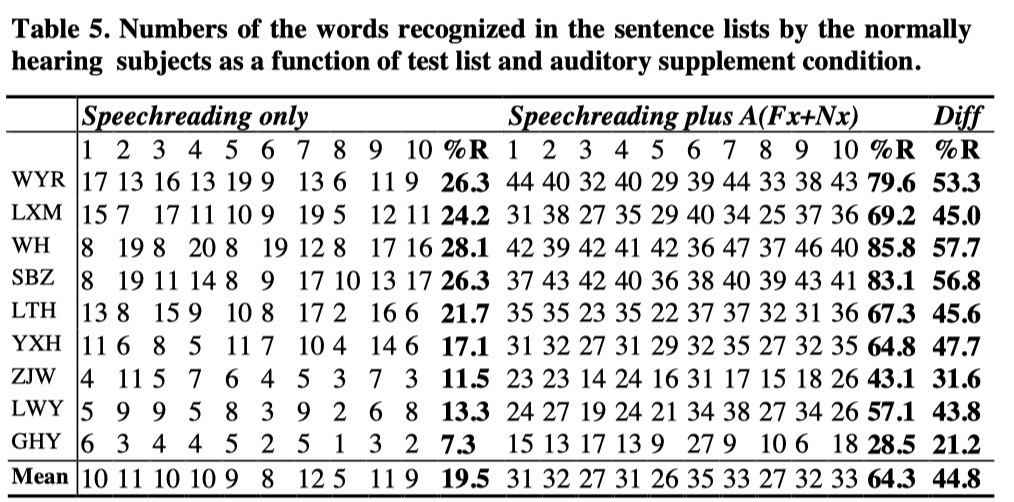
All the normally hearing subjects’ result were shown in the Table 5. It will be seen from Table 5 that all the subjects gained substantial benefits from the auditory supplement.
Discussion
The average enhancement effect of A(Fx+Nx) to speechreading sentences is 44.8% percent correct words for the normally hearing subjects, which is higher than that in the isolated word recognition tests (35.8%). This suggests that the subjects were able to obtain useful suprasegmental, linguistic information from the auditory signal.
Enhancement effect was present for all subjects, regardless of unaided speechreading score. The supplement effect of SiVoIII to speechreading covered a range from 21.2% to 57.7%. For nine normally hearing subjects, their supplemented scores were highly related to their unaided scores [r(9)=0.965, p<0.05]. When expressed as a difference of percentage score, the enhancement effect averaged 44.8%, with a tendency to rise with increasing speechreading score [r(9)=0.908, p<0.05].
In sentence recognition test, recognition of words in sentences was usually not measured (Boothroyd et al., 1988; Hanin et al., 1988; Eberhardt et al., 1990). In this study, recognition of sentences was also measured in order to compare these two different scoring methods.
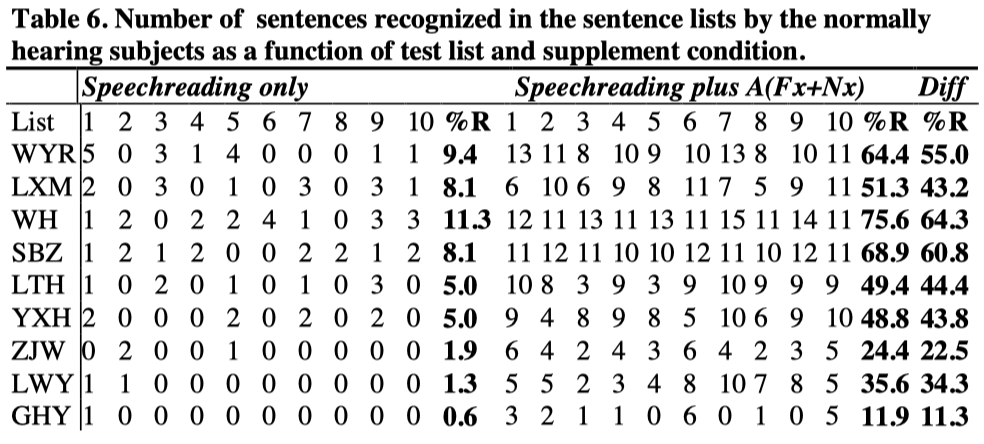
Linear regression analysis on the data in Table 5 and Table 6 show that the two scoring methods were very highly correlated [r(9)=0.992, p<0.05 for aided speechreading; r(9)=0.984, p<0.05 for difference; and r(9)=0.961, p<0.05 for speechreading alone].
Isolated sentence recognition by the profoundly hearing-impaired subjects
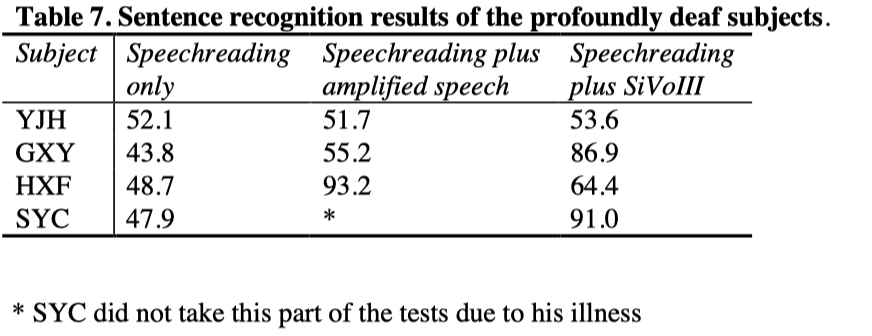
Four hearing impaired subjects did the sentence recognition test and Table 7 shows the scores.
It will be seen from Table 7 that the prelingually deaf subject YJH did not obtain significant help from the auditory supplement. The other three deaf subjects were able to obtain substantial help from the auditory supplement of amplified speech and SiVoIII. To the subject GXY, SiVoIII gave more help than amplified speech, but to the subject HXF, amplified speech gave more help than SiVoIII. No data was collected on the subject SYC with the supplement of amplified speech.
Conclusion
All the hearing subjects were able to extract substantial enhancement effect from the auditory supplement of compound speech pattern element signal, regardless of speechreading ability. For isolated word recognition, the enhancement effect, expressed as a difference of percentage score between supplemented and unsupplemented speechreading was 35.8%, and for isolated sentence recognition, the difference was 44.8%.
The hearing impaired people in this study showed large diversity. Subject SYC obtained nearly the same level of enhancement effect from the auditory supplement of SiVoIII (40.4% for word recognition, 43.1% for sentence recognition). Subject HXF did better with amplified speech than with SiVoIII but subject GXY gained more help from the supplement of SiVoIII than that from amplified speech. No substantial enhancement effect of the auditory supplement was observed from the prelingually deaf subject YJH.
More hearing-impaired people with profound hearing losses are needed to be tested in order to evaluate the speech pattern element method for Chinese deaf people. It seems highly possible that there will be great differences between different hearing-impaired people. Prelingually deaf people are not suitable for comparison experiment like this study.
Acknowledgment
The authors wish to thank all the subjects who participated in the experiments, Dr. Yuancheng Deng for searching for hearing-impaired subjects, and John Walliker and Julian Daley for supplying SiVoIII hearing aids. The study is jointly supported by the Laryngograph Trust, the Graduate Research Fund, UCL, and the OSCAR project.
References
Boothroyd, A., Hnath-Chisoim, T., Hanin, L. and Kishon-Rabin, L. (1988). “Voice fundamental frequency as an auditory supplement to the speechreading of sentences”, Ear and Hearing, 9, 306-312.
Boothroyd, A. (1988). “Perception of speech pattern contrasts from auditory presentation of voice fundamental frequency”, Ear and Hearing, 9, 313-321.
Breeuwer, M. and Plomp, R. (1984). “Speechreading supplemented with frequencyselective sound pressure information”, J. Acoust. Soc. Am., 76, 686-691.
Breeuwer, M. and Plomp, R. (1985). “Speechreading supplemented with formant frequency information from voiced speech”, J. Acoust. Soc. Am., 77, 314-317.
Breeuwer, M. and Plomp, R. (1986). “Speechreading supplemented with auditorilypresented speech parameters”, J. Acoust. Soc. Am., 79, 481-499.
Ching, Y. C. T. (1986) “Voice pitch information for the deaf”, in: Engell UCL, et al., ed.
Towards better communication, cooperation and coordination, Proc. of the First Asia Pacific Regional Conference Deafness, Hong Kong, 340-343.
De Filippo, C. L. and Scott, B. L. (1978). “A method of training and evaluating the reception of ongoing speech”, J. Acoust. Soc. Am., 63, 1186-1192.
Eberhardt, S. P., Bernstein, L. E., Demorset, M. E. et al., (1990). “Speechreading sentences with single-channel vibrotactile presentation of voice fundamental frequency”, J. Acoust. Soc. Am., 88, 1274-1285.
Erber, N. (1972). “Speech envelope cues as an acoustic aid to lip-reading for profoundly deaf children”, J. Acoust. Soc. Am., 51, 1224-1227.
Erber, N. (1979). “Speech perception by profoundly hearing impaired children”, J Speech Hear. Res., 44, 255-270.
Faulkner, A. and Fourcin, A. J. (1989). “Speech pattern presentation to the deaf: Speech perception and production”, Proc. of Euro-speech, 718-721.
Faulkner, A., Ball, V. and Fourcin, A. J. (1990). “Compound speech pattern information as an aid to lip-reading”, Speech, Hearing and Language: Work in Progress, Dept. of Phonetics, UCL, 4, 63-80.
Faulkner, A. et al. (1992). “Speech pattern hearing aids for the profoundly hearing impaired:Speech perception and auditory abilities”, J. Acoust. Soc. Am., 91, 2136-2155.
Fourcin, A. J. (1986) “Hearing aids for tonal languages”, in: Engell UCL, et al., ed. Towards better communication, cooperation and coordination, Proc. of the First Asia Pacific Regional Conference Deafness, Hong Kong, 72-83.
Fourcin, A. J. (1990). “Prospects for speech pattern element aids”, Acta Otolaryngol (Stockh) Suppl. 469, 257-267.
Hanin, L., Boothroyd, A. and Hnath-Chisolm T. (1988). “Tactile presentation of voice frequency as an aid to the speechreading of sentences”, Ear and Hearing, 9, 335-341. Howard, I. S. and Huckvale, M. A. (1988). “Speech fundamental period estimation using a trainable pattern identifier”, Proc. Speech 88, 7 th FASE Symposium. Edinburgh: Institute of Acoustics, 129-136.
Matthies, M. L. and Carney, A. E. (1988). “A modified speech tracking proccedure as a communicative performance measure”, J. Speech Hear. Res. 31, 393-404
Risberg, A. and Lubker, J. (1978). “Prosody and speechreading”, Speech Transmission Lab.Q. Prog. Stat. Rep. 4, 1-16.
Rosen, S. M., Moore, B. C. J. and Fourcin, A. J. (1979) “Lipreading with fundamental frequency information”, in: Proc. of the Institute of Acoustics Autumn Conference, 5-8. Rosen, S. M., Fourcin, A. J., and Moore, B. C. J. (1981) “Voice pitch as an aid to lipreading”, Nature, 291, 150-152.
Rosen, S., Faulkner, A. and Reeve K. (1994) “Voicing, fundametal frequency, amplitude envelope and voiceless excitation as cues to consonant identity”, Speech, Hearing and Language: Work in Progress, Vol. 8, 235-241.
Tye-Murray, N. and Tyler, R. S. (1988) “A critique of continuous discourses as a test procedure”, J. Speech Hear. Disord. 53, 226-231.
Walliker, J. R. and Howard, I. S. (1990) “The implementation of a real time speech fundamental period algorithm using multi-layer perceptions”, Speech communication, 9, 63-71.
Wei, J., Fourcin, A. and Faulkner, A. (1990). “A multi-layer perception classifier for robust Chinese frication/Vocalic detection”, ICSLP 90, Kobe, Japan, 31-12-1.
Wei, J., Faulkner, A. and Fourcin, A. J. (1991). “An application of speech processing and encoding scheme for Chinese lexical tone and consonant perception by hearing impaired listeners”, Proc. of Eurospeech’91, Genova, Italy.
Wei, J., Fourcin, A. J., and Faulkner, A, (1992) “Speech pattern processing for Chinese listeners with profound hearing loss”, Proc. of the 14 th ICA, Beijing, China.
Wei, J., Howells, D., Fourcin, A.J., and Faulkner, A. (1993) “Larynx period and frication detection methods in speech pattern hearing aids”, Proc. of Eurospeech ’93, Vol. 3, 2037-2049.
Zhang, J., Qi, S. et al. (1984). “On the important role of Chinese tones in speech intelligibility”, Chinese Journal of Acoustics, 3(3), 278-283.










