

28478 阅读 2020-07-10 09:55:02 上传
以下文章来源于 荷兰心理统计联盟
第七章 亚组分析


每个亚组分析由两部分组成:(1)每个亚组的合并后的效应量大小;(2)比较各亚组的效应量大小。
7.1.1 每个亚组的合并效应量
第一点很直接,正如没有亚组分析的单个元分析的标准一样(可以参考Chapter 4 and Chapter 4.2)。
<<<假设亚组中的所有研究都来自同一个群体,并且都存在真实的效应,这个时候可以使用固定效应模型进行分析。正如我们在第四章中提到过,即使把研究划分为亚组进行分析,很多人仍然怀疑这个假设在心理学研究和医学研究中是否真实可靠。
<<<因此,一个替代性方法是使用随机效应模型进行分析。该模型假设亚组内的被试是从一般性的群体中抽取出来的,我们想要使用随机效应模型估计其均值。
7.1.2 比较各亚组的效应量大小
在我们计算了各亚组的合并效应量之后,我们可以比较各亚组的效应量大小。然而,为了知道这种差异是否在实际上显著或者有意义,我们不得不计算亚组间效应量差异的标准误SEdiff,计算置信区间以及进行显著性检验。有两种基于差异假设的方法可以计算SEdiff。
<<<固定效应模型:当我们只对亚组比较感兴趣的时候,固定效应模型比较是合适的(Borenstein and Higgins, 2013)。这种情况就是当我们选择考察的亚组不是随机“选择”的,而且我们想要考察其特性的固定水平。性别的两个亚组“女性”和“男性”不是随机选择的,而是性别(在“传统”概念中分类中)所具有的两个亚组。同样的道理也适用于考察临床抑郁症与亚临床抑郁症患者是否会产生不同的效应。Borenstein and Higgins(2013)认为,可能对于医学、预防和其他领域的大多数研究来说,固定效应(复数)模型是唯一可行模型的。
由于该模型假设在亚组水平上没有进一步引入抽样误差(因为亚组不是随机样本,而是固定样本),SEdiff仅仅来源于亚组A和亚组B内的变异,即VA和VB。
VDiff=VA+VB
固定效应模型可以用来考察亚组之间合并后的效应量的差异,而亚组内的合并效应量仍然使用随机效应模型进行考察。这种组合方式被称为混合效应模型。我们将会在下一章展示如何在R中使用混合效应模型。
<<<随机效应模型:当我们使用的亚组是从一个亚组的总体中随机抽取的样本时,亚组间的随机效应模型更适用。例如,通过考察来自五个不同国家(例如,荷兰、美国、澳大利亚、中国和阿根廷)的干预研究,我们想考察这一个干预的效果是否因地区不同而所有差异。变量“region”有许多不同的潜在的亚组(国家),我们从其中随机选择了五个亚组。这意味着我们引入了一个新的抽样误差,我们不得不使用随机效应模型来控制亚组之间的抽样误差。
使用该模型估计VDiff的公式(简化)如下:

在这里,T(^)G2是亚组间的被估计的变异性,m是亚组的数量。
值得注意的是亚组分析应当总是基于已知的、先验的决策,即研究中哪个亚组的差异可能实际上是相关的,并且可能会导致在该研究领域的相关研究问题的信息获取。最好在进行分析之前指定亚组分析,并将其列出在分析注册中。同样重要的是要记住,亚组分析在检测研究之间有意义的差异的能力是有限的。亚组分析也需要足够的检验力。当元分析中的研究总数小于k=10时,比较两个或多个亚组是没有意义的(Higgins and Thompson, 2004)。
为了使用混合效应模型(亚分组内使用随机效应模型,亚分组间使用固定效应模型)进行亚组分析,可以使用提前准备好的subgroup.analysis.mixed effects函数。这个函数也是dmetar包的一部分。如果已经在R或Rstudio里安装了dmetar包,我们首先要加载它。
library(dmetar) ## 载入dmetar如果您不想使用dmetar包,您可以在原书的此处链接中找到这个函数的源代码。在这种情况下,R还不知道有这个函数。我们需要将整个代码复制并粘贴到RStudio的Console(左下窗格的控制台)中,然后按回车。该函数需要meta package才能运行。
对于subgroup.analysis.mixed.effects这个函数,需要设置以下参数:

在我的madata数据集中,已经生成过元分析输出m.hksj,存储在亚组的“Control”变量中。该变量特指哪个研究使用哪种类型控制组。有三个亚组:WLC(waitlist control),no intervention and information only。
使用具有这些参数的混合效应模型进行亚群分析的函数如下:
subgroup.analysis.mixed.effects(x = m.hksj,
subgroups =madata$Control)
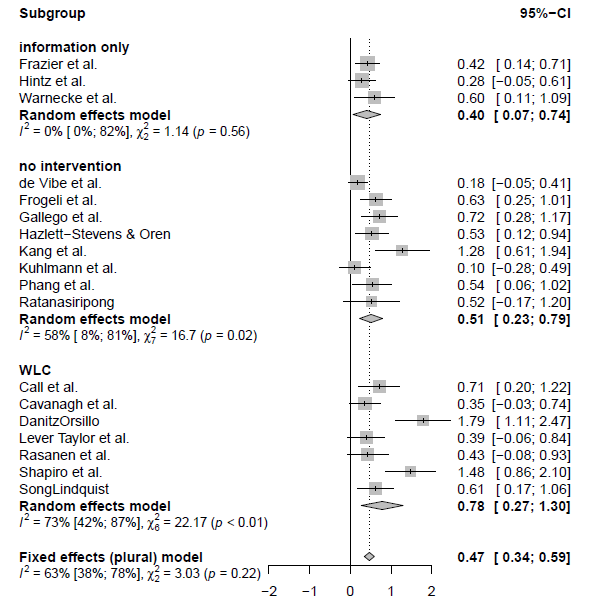
## Subgroup Results:


## Test for subgroup differences (mixed/fixed-effects (plural) model):

亚组分析结果显示在subgroup results之下。我们还看到,亚组的合并效应差异相当大(g = 0.41-0.78),但这种差异是没有统计学意义的。这可以在Test for subgroup differences (mixed/fixed-effects (plural) model) 中看到组间的差别。我们可以看到Q = 3.03, p = 0.2196。这些信息可以在我们的元分析的论文中报告出来。
现在,假设我们想知道在我们的元分析中干预效果是否因地区不同其干预效果有所差异。我们使用随机效应模型,并且选择了“阿根廷”、“澳大利亚”、“中国”和“荷兰”进行分析。
接着,我们再次使用m.hksj元分析输出对象。我们通过使用update.meta这个函数对亚组进行随机效应模型分析。对于update.meta函数,我们需要设置两个参数。

region.subgroup <- update.meta(m.hksj,byvar = region,comb.random = TRUE,comb.fixed = FALSE)region.subgroup


这里,我们获得了每个亚组(国家)的合并效应量。在检验亚组差异(随机效应模型)时,我们可以看到Test for subgroup differences (random effects model) 结果是不显著的(Q =4.52,p =0.3405)。这意味着我们并没有在不同地区的总体效应方面发现差异。
7.3.1亚组内的合并效应量使用固定效应模型,亚组间的差异使用固定效应模型
为了将固定效应模型与固定效果模型联合使用,我们还可以再次使用 update.meta这个函数。操作步骤和我们之前描述的一样,但是必须设置comb.random=FALSE 和 comb.fixed=TRUE。









