

1687 阅读 2020-07-25 09:42:02 上传
以下文章来源于 奈提柯斯先生
R语言
Recap
使用getwd( )函数可以查看当前的工作目录/路径,使用setwd( )函数可以对工作目录进行更改。
向量可以储存一维数组,保存的数据类型必须统一,使用c( )函数实现向量存储。
矩阵可以存储二维数组,使用matrix( )函数可以创建一个矩阵。
数组是矩阵的延展,可以创建多维数组,使用array( )函数可以创建一个数组。
数据框是最常见的数据结构,可以包含不同类型的数据,使用data.frame( )函数可以创建一个数据框,使用$可以对数据框的内容进行索引。
列表是最复杂的数据结构,可以包含若干向量、数据框等数据,使用list( )函数可以创建一个列表。

R: The R Project for Statistical Computing
https://www.r-project.org/
R Project
Linguistics
1
输入数据
在输入数据的时候,我们可能需要对数据进行编辑处理,但是很多人又对命令语句编写“发怵”,有没有其他的办法呢?自然是有。R中有一个Rcmdr包,为我们提供了基本的数据编辑功能,而且这个编辑功能为我们提供了一个可视化窗口,这也就意味着我们可以通过窗口来实现对数据的基本编辑。使用install.packages("Rcmdr", dependencies=TRUE)来安装该包并library(Rcmdr)来加载包。需要注意,这里我们需要添加dependencies=TRUE,因为当我们安装包的时候,是默认安装我们所选的包,而Rcmdr包有一系列它所需要“依仗”才能运行的其他包,设置好dependencies=TRUE就能安装完所有它所需要的包了。
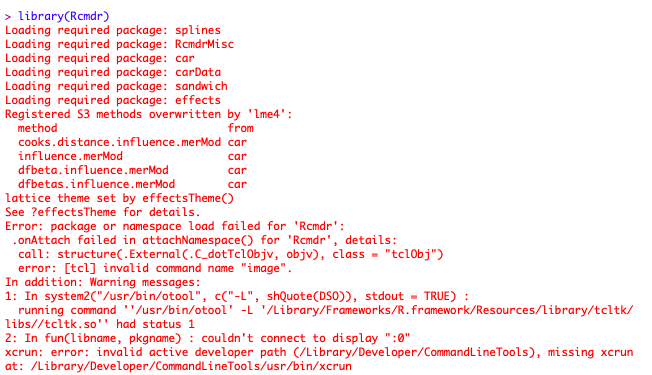
Mac OS系统会报错
需要注意,如果你使用的是Mac OS系统,那么会遇到频频报错的情况,这是因为需要一个Windows系统窗口才能弹出。因此针对Mac OS用户,可以下载并安装XQuartz(https://www.xquartz.org/),在运行R前率先运行XQuartz,然后再调用Rcmdr包,就可以正常运行了。可以看到,在R Commander窗口我们可以进行简单的数据编辑了。
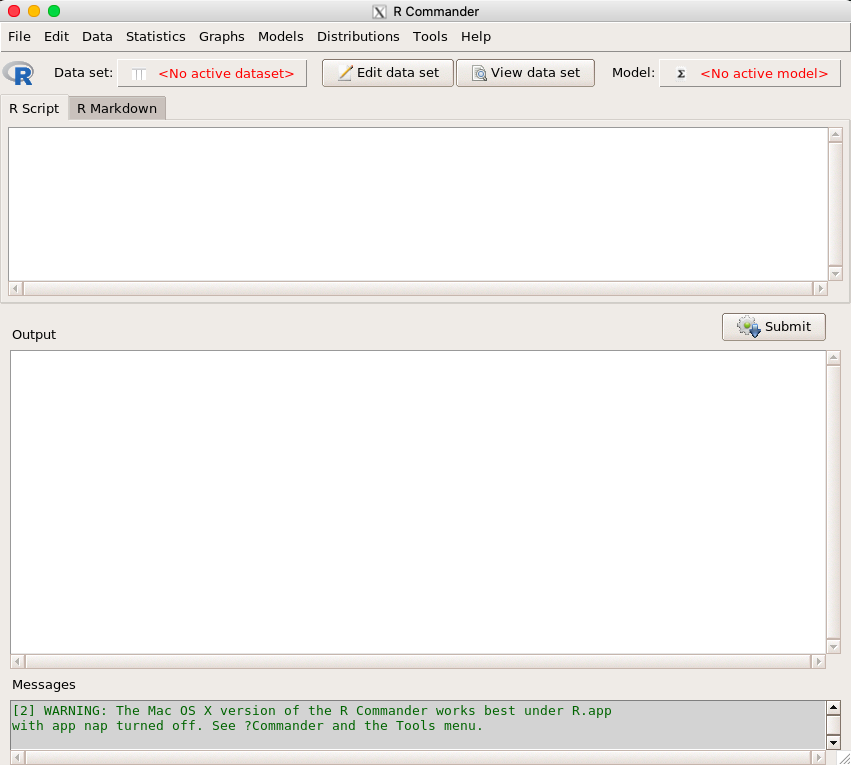
R Commander窗口
使用这个窗口界面来输入数据很简单,首先我们点击上方的Data,选择New data set,在设置好名称后点击确定。接下来在窗口中输入数据的方式和SPSS相似,点击第一栏可以设置变量名以及变量类型,之后可以对数据进行输入,这样我们就创建好了一个数据集。
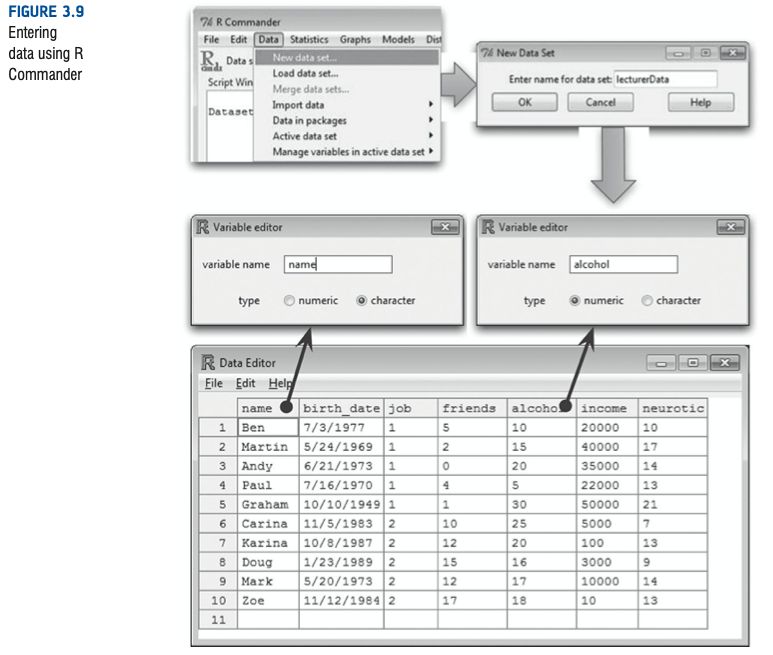
Discovering Statistics Using R, P. 94
我们可以看到,在R中也可以采用窗口的方式,实现简单的数据输入和编辑功能。但是我们所处理的数据是海量的,甚至有的数据在实验过程中就自动以一种格式存储了,这时候我们就不能使用这样的方式输入数据了,需要采用其他的导入方式来将我们所需的数据导入到R中。
R Project
Linguistics
2
导入数据
很多时候,我们通过Excel、text文档、SPSS等进行数据的输入,存储数据的格式也各式各样,因此我们需要想办法把数据导入到R。其中,foreign包可以直接把SPSS (.sav)、Stata (.dta)、Systat (.sys, .syd)、Minitab (.mtp)、SAS (XPORT files)等等数据导入到R。而最简单最直白的方法,无非是保存数据的时候就采用R“认可”的文件格式,直接导入到R。
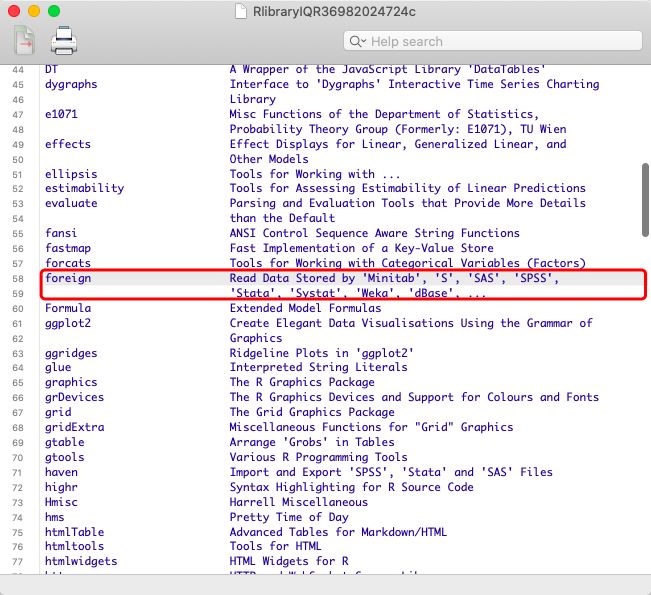
使用library( )(不写参数)可查看安装了哪些包
对于R可接受的数据格式来说,主要有两种类型最为“友好”,一类是以Excel导出的.txt和SPSS导出的.dat文件为主的制表符分隔文档(tab-delimited text),一类是以.csv(Excel、文本文档等都可以以该格式导出)为主的逗号分隔值文档(comma-separated values,也叫字符分隔值)。这三种格式的文档也是最常见的,我们在Excel、SPSS等中拿到数据后,选择“另存为”并更改储存格式,就可以导出上述格式的文档了,从而方便导入R。
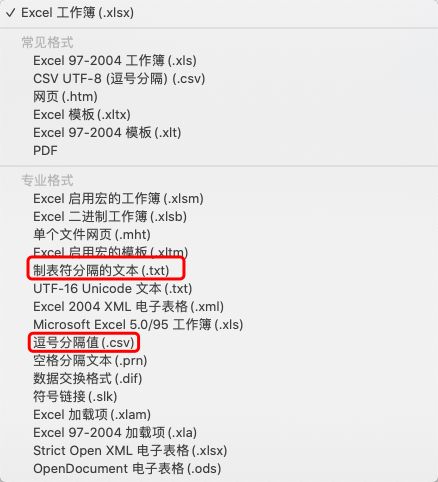
Excel中可选的格式
如果数据以CSV格式保存,我们可以把数据以数据框的形式导入到R,使用read.csv函数并选择你的数据文档即可。如果在这之前你首先把R的工作目录变更到你的数据所在路径下,那么直接使用read.csv("文件名.后缀名", header=TRUE)即可。如果并没有设置工作目录,那么就得要把完整的路径写下来了(这也是为什么建议大家更改工作目录)。

在命令中,你看到有一个header=TRUE的东西,这个命令语句是告诉R,在我数据的第一行存储的是变量名称。如果你的数据文档第一行并没有设置变量名,那么就改成header=FALSE即可。一般情况下我们的数据不会是孤零零的数字,都会有一个变量名表示这些数据是啥。所以,TRUE就对了。
既然我们知道了.csv格式的数据如何导入,那么制表符分隔的txt或dat也就很容易了,这时我们需要read.delim函数来导入这些数据,导入方式和read.csv是一致的,你可以拿一些文本来实验一下。

尽管我们可以借由以上方法(输入路径,或设置路径再导入)来导入我们的数据,但是很多人还是更习惯借助窗口选择来导入数据,这也是最为简便的方式。R为我们提供了file.choose( )函数,使用该函数可以弹出一个窗口,从而让你实现“鼠标点点选数据”的方法,省去了敲打命令语句的烦恼。

使用file.choose函数
这里我们要提一提另外一个函数read.table,一些有经验的R使用者会使用这个函数来导入数据。这个函数可以导入表格格式(一个矩形式样的数据)的文件并存储为数据框。与上述调用方式一样,可以加入file.choose来点选文件,然后选择你所需要的文件即可。可以看到,只要是表格型(或者说是矩形)的数据,我们都可以用该函数实现调用。

这时有人会问,我就是想直接调用SPSS的文件,当时做实验的时候都已经搞好了,不想改格式,怕转格式出问题,该怎么办?这就需要我们前面提到的foreign包了。在该包中提供了直接导入SPSS的函数read.spss,但是麻烦的是它需要其他的命令。

可以看到,除了选文件之外,use.value.labels=TRUE表示如果SPSS中某变量是作为因子/因素(factor)出现的,那么导入的时候要以factor存储,如果是FALSE,那么就会变成数值型变量。什么意思呢?比如我们在SPSS中使用1表示男性,2表示女性,如果你设置的是TRUE,那么它们就会以factor导入R,R在处理的时候会把它们认作是因素。如果设置FALSE,那么这些就变成了普通的数字毫无意义。第二句的to.data.frame=TRUE表示把数据以数据框形式保存,如果没有这个,你将收获乱糟糟的毫无头绪的数据。
最后,我们稍微提一提如何保存数据。我们花了这么长时间导入、处理、分析数据,我想保存下来,很简单。首先我们要明确一点,保存的时候使用制表符分隔或逗号分隔,这样方便我们使用Excel等软件打开。保存制表符分隔文件,使用write.table函数,具体格式为write.table(dataframe, "filename.txt", sep="\t", row.names=FALSE)。其中sep="\t"表示使用制表符分隔,当然你也可以使用空格或逗号来表示我使用什么方法来分隔数据。row.names=FALSE是告诉R别导出行号。在数据展示中你可以看到,R最前面会有一个行号,这个就是防止R导出它以防扰乱我们的数据。比如:write.table(mydata1, "aver_dur.txt", sep="\t", row.names=FALSE)。

最前面的行号
导出CSV文档就简单了,使用write.csv函数即可,具体格式为write.csv(dataframe, "filename.csv"),它的sep是默认值不用管,这样就能导出csv文件了。比如write.csv(mydata1, "aver_dur.csv")。相对于write.table而言,它显得十分清爽友好。具体保存什么样的数据,还是要看你的选择。











