1914 阅读 2020-07-25 09:46:02 上传
以下文章来源于 荷兰心理统计联盟
心理学部双创中心「心理学101工作室」特约来稿 | 本文由北师大心理学部 BAC 方向周阳老师及19级学生团队原创,项目中数据爬取、预处理、分析、推文写作等流程皆由团队独立完成


1:项目整体流程
项目之初,我们需要从目标出发,梳理项目的整体流程,拆解任务,并借助项目流程表立下每个关键节点的flag。以下是我们所做的项目整体推进表:
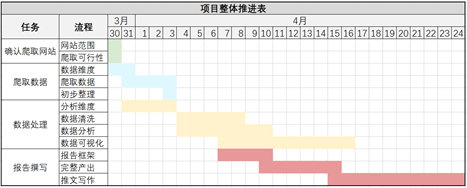
以本项目为例,我们首先需要确定项目需求,即通过爬取招聘网站,了解心理学专业的主要就业岗位及相关信息,为同学们的就业提供客观参考。
然后再把这一需求划分成具体的任务步骤例如确定爬取网站及数据维度、获取数据、数据预处理等关键节点。【详见下part】最后针对每个任务的进度和项目组的整体时间确定合适的DDL和项目汇报时间以及相应的负责人。
2:数据分析
2.1
数据获取
获取数据需要考虑三个问题:从哪里获取,是否可行,如何实现。以下为本次项目数据获取详细过程,仅供参考。
2.1.1 确定数据来源
首先需要确定选取哪些招聘网站作为数据来源。我们分别从蝉大师(APP排行)、站长之家和百度风云榜收集了各招聘网站的评价以及使用程度,综合考虑网站的知名度和匹配度后,确定了七个候选网站。
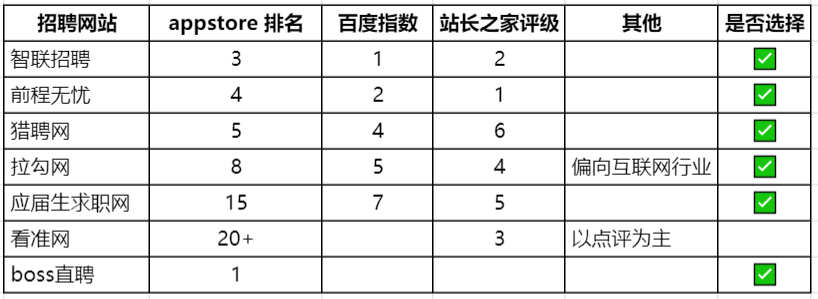
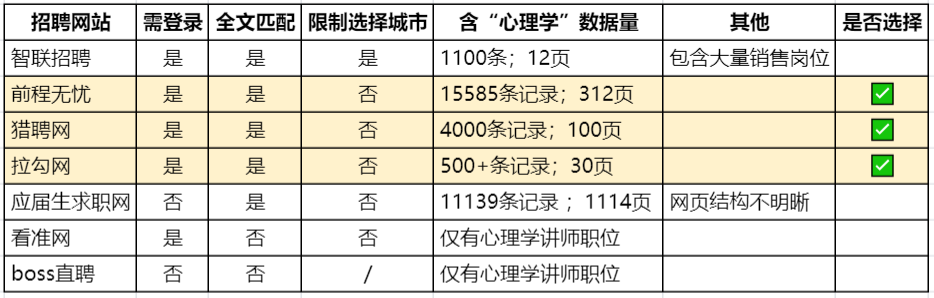
2.1.2 获取可行性
明确招聘网站的范围之后,需要结合数据分析需求和网站的招聘信息确定目标网站。招聘网站的网页特点如下图所示,综合考虑数据的质量和数量,我们最终选取前程无忧、猎聘网和拉勾网作为数据来源。
2.1.3 数据爬取
明确数据源后,就可以开始着手爬取数据了。
如果你有一定编程的基础,可以自己编写爬虫代码。因为网上有很多爬取网站的代码框架,也可以借鉴现有代码进行修改。
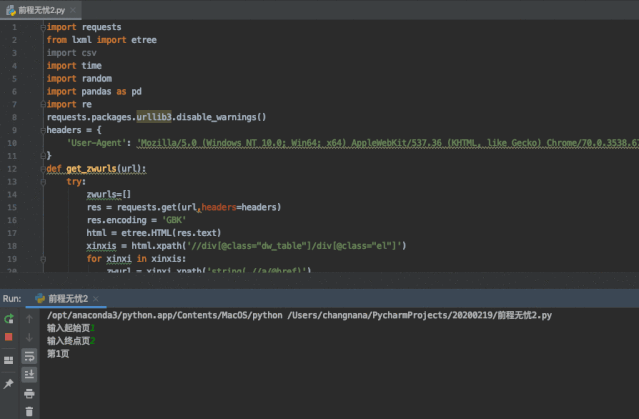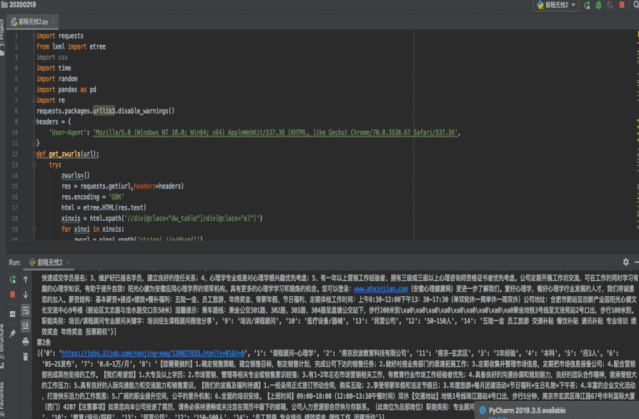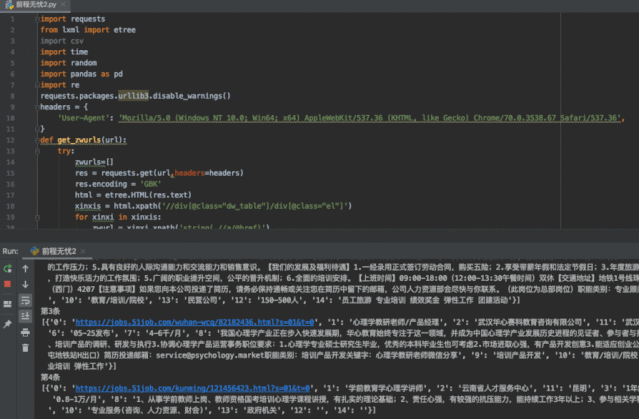
如果你目前还没接触编程语言,借助爬虫工具也可轻松爬取数据:例如八爪鱼,webscraper等。这类工具操作简单教程多,但需要提前了解目标网站是否在工具可爬取范围,大家可自行百度~

2.2
数据预处理
爬取完数据,满心欢喜打开excel,当我们以为接下来就是数据分析大展拳脚的时候,现实就像你爬取的结果,充满了乱码、缺失值和无效信息,让你的ddl险些去世。

大部分情况下,获取的数据并不能直接进行分析。原始数据中会夹杂着许多(始料未及的)无效数据,它们会直接影响最后的分析结果,因此需要针对具体问题制定规则进行处理。以下为本项目使用的数据预处理方法。

小提示:凡是涉及数据处理的时候,一定要保留原始数据。否则一旦出现错误,你只能一边哭一边重新爬数据。
数据规范化作为预处理中工作量最大、耗时最长的一步,值得举两个栗子来帮助大家理解:
薪资规范化
如下图中的“原始数据”,招聘网站中展示的薪资信息存在多种呈现方式,无法直接进行比较和分析。因此,我们需要将不同格式的薪资信息统一标准(以元为单位的月薪),据此生成“最大值”、“最小值”、“平均值”三个衍生变量,并将“平均值”映射到更高层次的“薪资区间”,方便后续进行描述统计。

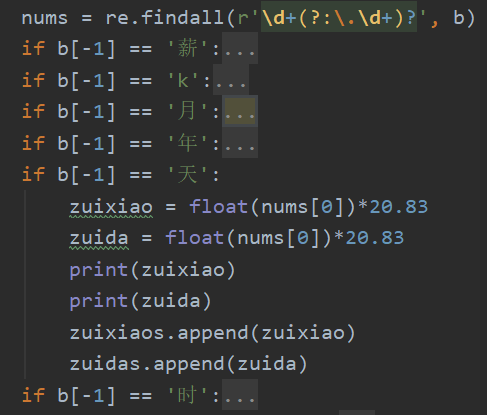
正则表达式( Regular expression)是一组由字母和符号组成的特殊文本, 它可以用来从文本中找出满足你想要的格式的句子。在你学会正则之前,只能看着那些大佬们用短短一行外星文,替代了你一整页的if else代码。(下图是身份证号码的正则校验)
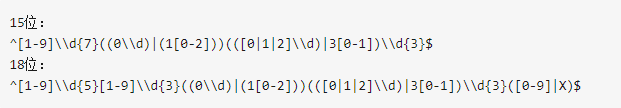
然而,正则表达规则比较复杂,在此不做赘述,有兴趣的小伙伴可以看下面的一个教程:
Python“正则表达式”详解(上):http://suo.im/6gg0m3
Python“正则表达式”详解(下):http://suo.im/5wsPQ2
地区规范化
原始数据中的“工作地点”同样存在标准不统一的问题,为方便后续统计分析,需要将(五花八门的)地点信息统一为规范的省份名称。在此我们主要介绍如何批量把城市映射到所属省份。
此处不需要任何编程基础,用Excel就可以实现。首先需要从网上下载城市和省份的对应数据,然后通过Excel的INDEX+MATCH函数,轻松解决数据查找匹配问题。

2.4
数据分析
2.4.1 明确分析思路
做完数据预处理后,终于来到了数据分析的环节!一开始,我们坐拥一万多条有效数据、二十多个维度,用Excel的数据透视表迅速得到了各个维度的分布结果,然后在准备写推文时忽然发现不知从何下笔,也不知道有些图表的展示有什么意义。
以上,便是以数据为导向来决定分析思路的反面教材。面对维度众多的数据,容易走入一味晒数据的死胡同,难以提供有价值的结论,而更有效率的分析思路应该以解决问题为导向。从问题出发,反推分析方法和所需要的数据维度。
在第二轮寻找思路的过程中,我们首先定位了文章的受众:心理学爱好者、学生以及从业人员。随后开始定位问题:他们会对什么感兴趣?什么样的结论对他们而言是有意义的?最后由问题得出文章框架及分析思路。

2.4.2 具体分析方法及工具
有了整体的报告结构以及具体的分析内容,接下来就进入具体的分析阶段了。数据分析的工具有很多,需要根据分析需求进行选择,同时辅以可视化的需求(可视化稍后再细谈)。以本次项目为例,主要有四类分析需求,即描述性分析、交叉分析、时序分析以及文本分析。

描述性分析和交叉分析的部分,出于美观以及操作便捷性的考虑,我们选取了Tableau和Excel。
时序分析希望展示的是数据在时间维度上的变化趋势,而动态效果更能体现这种变化趋势,因此,我们选取了Flourish数据跑分软件。
文本分析常见的用途是从大量文本中提炼主题或关键字,比较简单的方法是对词频进行统计分析。但单纯的词频统计往往会遇到高频无意义词(例如“一个”、“的”)和单个词语意义有限两个问题。以“岗位关键能力”分析为例,我们希望在岗位描述中,提取出反映岗位要求的信息。为解决上述问题,我们选择了将TF-IDF算法与n-gram结合使用。

TF-IDF算法可在计算词频时引入权重,从而排除在一般场景下词语使用频率的影响,得到在特定语境中的真实高频词。
n-gram是从一个句子中提取n个连续词的集合,可以获取到词的前后信息。经试验我们选择了1-gram、2-gram、3-gram和4-gram四种组合的结果。

3:数据可视化
人的认知资资源是有限的,外加互联网时代信息爆炸的特点,二者促使人们的阅读习惯逐渐向读图时代步进。好的可视化内容可以辅助读者快速理解文字内容,增强可读性。下图简单总结了本项目中使用到的可视化工具及使用场景,仅供大家参考。