5436 阅读 2020-08-25 09:17:02 上传
以下文章来源于 奈提柯斯先生
R语言
语言学与R语言的碰撞
Xu & Yang
PhoneticSan

学习参考
Discovering Statistics Using R
Statistics for Linguistics with R
How to Do Linguistics with R
R in Action
Analyzing Linguistic Data
R Graphics Cookbook
··· ···
Recap
假设检验的主要逻辑是:陈述零假设,选择显著性水平,确定统计方法,计算统计量,计算拒绝域,作出统计推断。
显著性水平本质上是一个概率值,它计算的在零假设为真的情况下非常不可能出现的情况。。
Type I error指的是研究结果出现了处理效应,拒绝了H0,但实际上并没有出现处理效应,这种情况是由于样本选取到了极端值。
Type II error指的是假设检验没有检测到处理效应导致研究者接受了H0,这种情况是由于处理效应过小而没有检测到。
双尾检验要求比单尾检验更为严格,单尾检验具有强烈的方向性。但是当双尾检验没有出现显著性差异时,不能再用单尾检验进行检测。

R: The R Project for Statistical Computing
https://www.r-project.org/
RStudio:
https://rstudio.com/
在之前计算z分数的时候,我们发现它必须需要知道总体标准差,然而我们做的语言学研究,总体的相关参数是未知的,我们只能搜集到从总体得来的样本数据。那么,我们如何比较样本之间平均数的差异呢?这时候我们采用t统计量(t-statistic)来进行统计分析,这种检验就是t检验(t-test),它适用于样本量较小(n<30)且总体标准差未知的情况。t检验可以分单一样本t检验(one-sample t-test),独立样本t检验(independent t-test)和配对样本t检验(dependent t-test, paired t-test)。其中单一样本t检验在语言研究中并不常用,因此我们主要详细介绍后面两类检验方法,以及在R中如何实现。
R Project
Linguistics
1
独立样本t检验
独立样本t检验是一种组间检验方法(between-groups t-test),它的数据主要来自于不同的样本,是一个典型的参数检验(parametric test),它有以下几个初始假设条件:
样本呈正态分布。
两个样本间彼此独立。
样本的测量范围一致。
总体的方差与样本大致相同(方差齐性)。
其中方差齐性(homogeneity of variance)实际上是比较两组数据的分布是不是保持一致,可以通过R自动计算,不用再我们手动计算了。下面,我们以一个实例来解释什么是独立样本t检验。

独立样本t检验示意图
独立样本t检验目的是评价两个总体(或者两个处理条件)之间对平均数差,因此它的零假设H0和备择假设H1当分别为:
H0:μ1 – μ2 = 0 (总体平均数之间没有差别)
H1:μ1 – μ2 ≠ 0 (总体之间不存在平均数差)
这里我们举个例子,比如我要检测男性发音人和女性发音人在阴平调值上有没有明显差异,这时我们需要比较的就是阴平调值的平均数差存不存在(这里仅做举例,之后我们会谈到更适合于声调/语调分析的统计方法)。为了进行独立样本t检验,我们首先要计算出两个样本各自的平均值,我们分别记作M1和M2。接着我们要计算出两个样本的标准误差,分别记作s1和s2。接下来,我们需要计算t统计量。
我们都知道,z分数的计算是离均差除以标准差,t统计量的计算与之相类似,它采用的是样本平均数的差异与总体平均数的差异相减,得到的差值除以样本估计的标准误得到。因为我们的H0是总体平均数之间没有差别,因此总体平均数差异的数值为0,最后得到的公式是样本平均数的差异除以估计的标准误差。

独立样本t检验中t统计量的计算公式
我们需要稍微解释下估计标准误差的由来。两个样本平均数分别代表了对应总体的平均数,但是毕竟是来自样本的数据,因此这些平均数总会存在一些偏差(误差),那么误差的来源就有两个了。在独立样本t检验中,我们想要知道由两个样本平均数来表示两个总体平均数的误差总量,这时我们可以采用方差和定理(variance sum law)来计算,它指出了自变量之间的差的方差等于各自变量方差之和。通过这个方式,我们得到了在独立样本t检验中,估计的标准误差的计算方法:
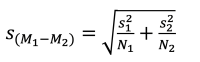
估计标准误差的计算方法
现在,我们知道了样本平均数之差,知道了标准误差,那么我们就可以得到独立样本t检验中t统计量的计算方式:

独立样本t检验t统计量的计算方式
计算出相关统计量后,我们需要计算t临界值tcritical,这个值根据你的自由度和显著性水平来定义,可以通过各种统计学教材查阅表格。当你计算出来的t统计量小于表格中对应的t临界值,那么说明具有显著性差异。现在我们完全不需要再一个个查阅相关数据了,R会帮我们直接输出我们所想要的结果。
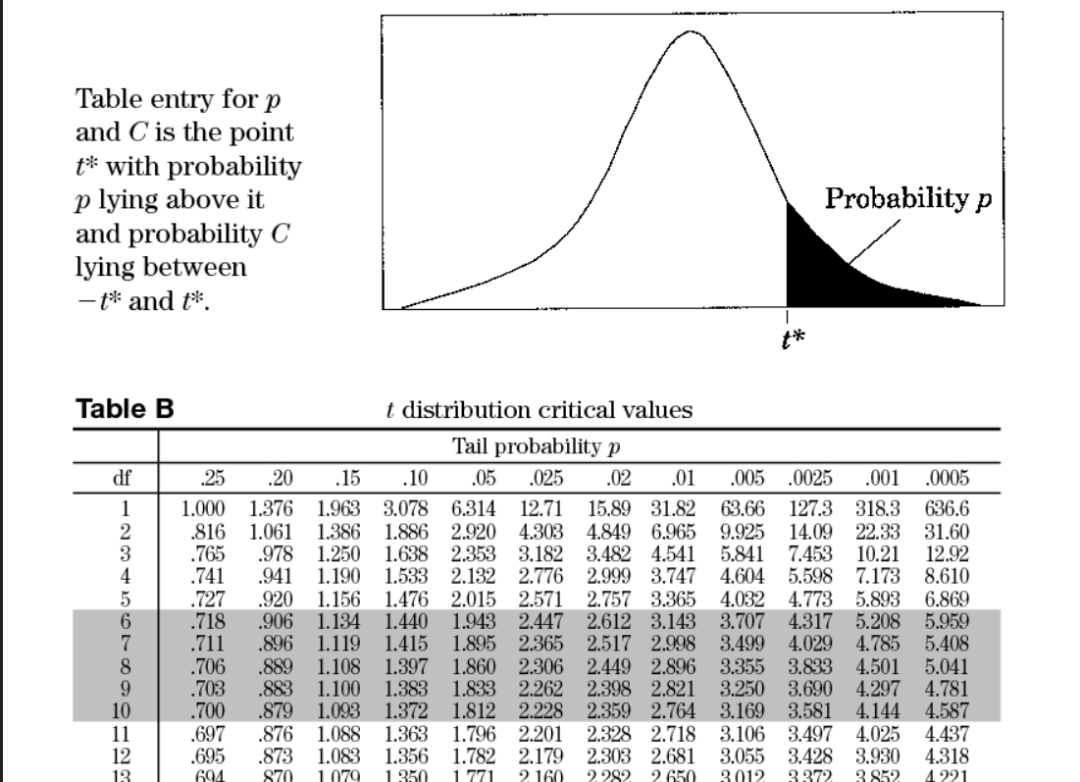
t临界值表
R Project
Linguistics
2
配对样本t检验
与独立样本t检验不同,配对样本t检验是从同一总体抽取出来的的两个样本,因此它又被称为组内t检验。比如,儿童元音习得的追踪实验,它是一个典型的纵向研究,提取了同一人不同时间段的元音发音情况,比较不同年龄时各元音习得程度,这时我们就可以采用配对样本t检验来检测该儿童是否真的在某一时期习得了某元音。此外,在我们语言学研究中最为常见的,是同一对象的不同水平,比如我们检测同一批发音人,在语句中有焦点和没焦点两个因素影响下音高有没有差异,这时候采用的就是配对样本t检验。常见的配对样本设计有:同一对象处理前后变化,同一对象两个部位数据,同一对象两个不同测量方法的数据,配对的两个对象分别接受两种处理后的数据。
配对样本t检验示意图
配对样本t检验的检验步骤和独立样本t检验的检验步骤是一致的,首先计算相关统计量,然后确定t临界值,进行统计推断。其中需要注意的是,配对样本t检验的t统计量计算公式与独立样本t检验的计算公式并不一样,具体如下图所示。它考虑了样本平均数之间的差异和总体平均数之间的差异,并进行比较。其中D指的是样本之间平均差,分母是是估计的样本平均数差值的标准误差,我们使用样本方差s和样本大小n来估计标准误差。

配对样本t检验计算公式
同样的,计算出你实验研究的t统计量后,与tcritical进行比较,从而判断是否具有显著性差异。配对样本t检验相较于独立样本t检验,其结果更具有有效性,因为它帮助研究者减少了由于不同研究对象而导致的差异。
R Project
Linguistics
3
使用R做t检验
在R中进行t检验非常简单,我们只需要调用t.test( )函数即可。我们可以首先观察下t.test( )函数的构成,可以看到我们只需调入数据即可,再使用paired=TRUE或paired=FALSE来控制我们使用的是配对样本t检验还是独立样本t检验。

R中针对t.test( )函数的示例
因为独立样本t检验和配对样本t检验的使用方法只有逻辑值的不同,因此我们只针对其中一个方法进行举例。我们以一开始的独立样本t检验中所提到的某方言男女阴平调值是否具有显著性差异进行检测,如果没有相关数据,您可以根据Discovering Statistics Using R一书第九章的内容进行试验。导入我们所需要的数据,然后调用函数t.test( )并设置好你要进行比较的数据名,比如这里我的数据名是male和female,那么我们使用索引在t.test( )函数中导入。因为是独立样本t检验,因此我们的paired的逻辑值为FALSE。我们就可以看到它计算出了我们所需要的统计量。
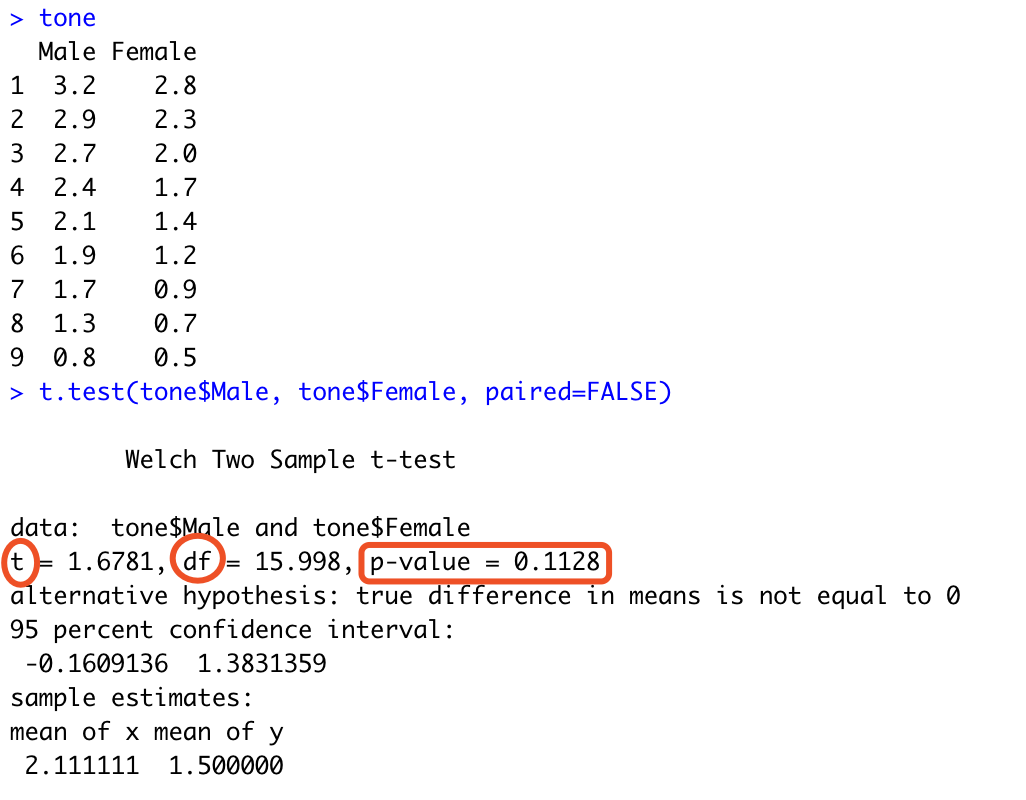
R中进行独立样本t检验
我们主要观察的是红框中的t值、自由度和p值。可以看到在我的这个数据中,并没有出现显著性差异。我们对这个统计结果应当进行这样的报告:
根据统计分析,男性发音人的平均阴平调值(M=2.11, SE=0.78)要比女性发音人的平均阴平调值(M=1.50, SE=0.77)高,并没有出现显著性差异,t(16)=1.68, p >.05。
需要注意的是,并不是p值越小说明差异越大,而是p值越小,越意味着我们有足够的理由拒绝我们的H0。在之后的统计检验中,我们还会经常用到p值。总体而言,t检验为我们提供了对样本平均值进行比较的方法,之后我们还会提及其他统计方法,届时会将不同统计方法进行比较。