

747 阅读 2020-09-18 10:37:02 上传
以下文章来源于 西语语言学工作坊
本篇记录我集群搭建的过程和问题,目标是可以根据本篇文章搭建自己生产可用的 K8S 集群。对于 K8S 的一些概念理解,可参考我之前的笔记Kubernetes 学习笔记-基础篇[1]。
文章较长,建议收藏备。
环境准备
容器环境对 Linux 的系统内核有一定的要求, kernel 3.10 是当前 Docker 19 可以稳定运行的最小的 Linux 内核版本。Docker 中应用了很多内核中的新功能,经过大量的实践证明,使用你当前发行版本 Linux 的最新稳定的内核是最佳的选择。
通过下边的脚本,可以检测依赖环境的可用性:
https://github.com/docker/docker/blob/master/contrib/check-config.sh
K8S 官方建议集群硬件最小配置为,2G 内存,2 个 cpu, 30G 硬盘。若集群仅作为学习使用,官方提供了 Minikube和Kind两种方式,可安装简易版的 K8S,来熟悉了解 K8S 的各种组件和功能。针对 Mac 用户,Docker for Mac的客户端也集成了 K8S 的功能,也可启用来体验。
Minikube和Kind方式安装 K8S 安装文档[2];Docker for Mac启用文档[3];
本次目标搭建生产可用的集群,环境准备如下:
6 台 Liunux 机器,CentOS 7.8, Kernel 3.10.0-1127.18.2.el7.x86_64 192.168.10.11 192.168.10.12 192.168.10.13 192.168.10.14 192.168.10.15 192.168.10.16 Docker: 18.09.9 Kubernetes: 1.16.14 (考虑到内核版本比较低,选择了较低版本,k8s 1.18 部署相同) ETCD: 3.4.9
环境规划
规划 K8S 的各组件机器如下:
ETCD
192.168.10.14 192.168.10.15 192.168.10.16 K8S Master
192.168.10.11 host: 10-11-master 192.168.10.12 host: 10-12-master 192.168.10.13 host: 10-13-master K8S Node
192.168.10.14 host: 10-14-node 192.168.10.15 host: 10-15-node 192.168.10.16 host: 10-16-node Nginx + Keepalived
192.168.10.14 192.168.10.15
这里 Node 和高可用组件都共用了 ETCD 的机器,这里仅作为演示说明,真实生产环境中建议都使用单独的机器部署,以免组件或机器故障相互影响。
环境初始化
以下操作,Master 和 Node 机器需要执行。
# 设置系统host,如192.169.10.11 host 为 10-11-master。其他机器修改方式相同。$ hostnamectl set-hostname 10-11-master$ echo "127.0.0.1 $(hostname)" >> /etc/hosts# 升级系统内核mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo_bakwget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repoyum clean allyum -y update# 关闭防火墙systemctl stop firewalldsystemctl disable firewalld# 关闭swapswapoff -ased -i 's/.*swap.*/#&/' /etc/fstab# 关闭SeLinuxsetenforce 0sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinuxsed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/configsed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/sysconfig/selinuxsed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/selinux/config# 设置内核参数cat </etc/sysctl.d/k8s.conf net.ipv4.ip_forward = 1net.bridge.bridge-nf-call-ip6tables = 1net.bridge.bridge-nf-call-iptables = 1net.ipv4.tcp_keepalive_time = 600net.ipv4.tcp_keepalive_intvl = 30net.ipv4.tcp_keepalive_probes = 10EOFmodprobe br_netfiltersysctl -p /etc/sysctl.d/k8s.confls /proc/sys/net/bridge# 配置资源限制echo "* soft nofile 65536" >> /etc/security/limits.confecho "* hard nofile 65536" >> /etc/security/limits.confecho "* soft nproc 65536" >> /etc/security/limits.confecho "* hard nproc 65536" >> /etc/security/limits.confecho "* soft memlock unlimited" >> /etc/security/limits.confecho "* hard memlock unlimited" >> /etc/security/limits.conf# 依赖安装yum install -y epel-releaseyum install -y yum-utils device-mapper-persistent-data lvm2 net-tools conntrack-tools wget vim ntpdate libseccomp libtool-ltdl# 安装Dockeryum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repoyum makecache fastyum -y install docker-ce-18.09.9 docker-ce-cli-18.09.9systemctl enable docker.servicesystemctl start docker.servicesystemctl stop docker.servicecat > /etc/docker/daemon.json << EOF{"exec-opts": ["native.cgroupdriver=systemd"],"registry-mirrors": ["https://4xr1qpsp.mirror.aliyuncs.com","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","https://registry.docker-cn.com"],"storage-driver": "overlay2","storage-opts": ["overlay2.override_kernel_check=true"],"log-driver": "json-file","log-opts": {"max-size": "100m","max-file":"5"}}EOFsystemctl daemon-reloadsystemctl start docker
组件安装
机器环境初始化好之后,开始搭建 K8S。主要有两种搭建方式:
kubeadm:官方提供的安装工具,除管理容器的组件 kubelet 外,其他组件均以容器的形式启动。可通过
kubeadm init和kubeadm join来快速实现 K8S 集群的搭建。官方地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/ 。更加详细的安装步骤,可参考扩展阅读 1。二进制方式搭建:K8S 的各组件都是使用 Go 语言开发的,发布运行都是编译好的二进制文件。该方式需要自己来安装每个组件,自己编写配置文件和管理启动文件。
初学者,本着学习的目的,本文记录第二种安装方式,以便熟悉 K8S 的各组件。老手完全可以使用 kubeadm 来快速搭建一个生产可用的集群。
在搭建集群之前,回忆下 K8S 的各组件。
 (图片来源网络)
(图片来源网络)
那我们梳理部署组件情况如下:
单独集群部署:
etcd 保存了整个集群的状态; Master 部署:
controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等; scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上; apiserver 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制; Node 部署:
kubelet 负责维护容器的生命周期,同时也负责容器卷插件 Volume(CVI)和容器网络插件(CNI)的管理; kube-proxy 负责为 Service 提供 cluster 内部的服务发现和负载均衡; Container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI);
下面开始。
1/ ETCD 集群的搭建
ETCD 主要用来保存集群状态和资源对象数据。使用 kubeadm 安装时,默认etcd集群和 Master 节点是在一块的。为提高可用性减少故障影响,建议将etcd单独部署一个集群,方便管理维护。
1.1/ 签发证书
为提高安全性,统一使用 ssl 加密。可使用自签证书,我们使用 cfssl 工具来生成证书。
# 下载cfssl 二进制文件wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64# 增加执行权限chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64# 移动到可执行目录mv cfssl_linux-amd64 /usr/local/bin/cfsslmv cfssljson_linux-amd64 /usr/local/bin/cfssljsonmv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
生成根证书
# 创建目录存放证书文件mkdir -p /opt/ssl/{etcd,k8s}# 创建根证书配置文件, 有效期为87600h(10年)。cd /opt/ssl/etcdcat > ca-config.json << EOF{"signing": {"default": {"expiry": "87600h"},"profiles": {"www": {"expiry": "87600h","usages": ["signing","key encipherment","server auth","client auth"]}}}}EOFcat > ca-csr.json << EOF{"CN": "etcd CA","key": {"algo": "rsa","size": 2048},"names": [{"C": "CN","L": "Beijing","ST": "Beijing"}]}EOF# 生成证书cfssl gencert -initca ca-csr.json | cfssljson -bare ca -lsca-config.json ca.csr ca-csr.json ca-key.pem ca.pem
签发 etcd https 证书
cat > server-csr.json << EOF{"CN": "etcd","hosts": ["192.168.10.14","192.168.10.15","192.168.10.16"],"key": {"algo": "rsa","size": 2048},"names": [{"C": "CN","L": "BeiJing","ST": "BeiJing"}]}EOF
hosts 为 etcd 的集群节点 ip, 改成你实际的 ip 即可。
1.2/ etcd 集群搭建
下载 etcd 二进制文件到三台事先准备好的机器,编写配置文件和启动管理文件。
# 创建etcd目录mkdir -p /opt/etcd/{bin,cfg,ssl}# 复制生成的证书到etcd证书目录cp /opt/ssl/etcd/ca*.pem /opt/etcd/ssl/cp /opt/ssl/etcd/server*.pem /opt/etcd/ssl/# 配置文件wget https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gztar zxvf etcd-v3.4.9-linux-amd64.tar.gzcd etcd-v3.4.9-linux-amd64cp -a etcd etcdctl /opt/etcd/bin/cat > /opt/etcd/cfg/etcd.conf << EOF#[Member]ETCD_NAME="etcd-1"ETCD_DATA_DIR="/var/lib/etcd/default.etcd"ETCD_LISTEN_PEER_URLS="https://192.168.10.14:2380"ETCD_LISTEN_CLIENT_URLS="https://192.168.10.14:2379"#[Clustering]ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.10.14:2380"ETCD_ADVERTISE_CLIENT_URLS="https://192.168.10.14:2379"ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.10.14:2380,etcd-2=https://192.168.10.15:2380,etcd-3=https://192.168.10.16:2380"ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"ETCD_INITIAL_CLUSTER_STATE="new"EOF
ETCD_NAME:节点名称,集群中唯一 ETCD_DATA_DIR:数据目录 ETCD_LISTEN_PEER_URLS:集群通信监听地址 ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址 ETCD_INITIAL_ADVERTISE_PEER_URLS:集群通告地址 ETCD_ADVERTISE_CLIENT_URLS:客户端通告地址 ETCD_INITIAL_CLUSTER:集群节点地址 ETCD_INITIAL_CLUSTER_TOKEN:集群 Token ETCD_INITIAL_CLUSTER_STATE:加入集群的当前状态,new 是新集群,existing 表示加入已有集群
# 编写启动管理文件cat > /usr/lib/systemd/system/etcd.service << EOF[Unit]Description=Etcd ServerAfter=network.targetAfter=network-online.targetWants=network-online.target[Service]Type=notifyEnvironmentFile=/opt/etcd/cfg/etcd.confExecStart=/opt/etcd/bin/etcd \--enable-v2 \--cert-file=/opt/etcd/ssl/server.pem \--key-file=/opt/etcd/ssl/server-key.pem \--peer-cert-file=/opt/etcd/ssl/server.pem \--peer-key-file=/opt/etcd/ssl/server-key.pem \--trusted-ca-file=/opt/etcd/ssl/ca.pem \--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem \--logger=zapRestart=on-failureLimitNOFILE=65536[Install]WantedBy=multi-user.targetEOF# 启动systemctl daemon-reloadsystemctl start etcdsystemctl enable etcd
复制 etcd 文件(/opt/etcd/下的所有文件,service 文件)到其他两个节点,并修改/opt/etcd/cfg/etcd.conf文件中 ip 为对应节点 ip,启动即可。
最后,查看节点状态。
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.10.14:2379,https://192.168.10.15:2379,https://192.168.10.16:2379" endpoint healthhttps://192.168.10.14:2379 is healthy: successfully committed proposal: took = 12.762896mshttps://192.168.10.15:2379 is healthy: successfully committed proposal: took = 12.974284mshttps://192.168.10.16:2379 is healthy: successfully committed proposal: took = 12.996147ms
至此,etcd 集群搭建完成。
2/ Kubernetes Master 节点部署
2.1/ 签发证书
生成根证书
cd /opt/ssl/k8s/cat > ca-config.json << EOF{"signing": {"default": {"expiry": "87600h"},"profiles": {"kubernetes": {"expiry": "87600h","usages": ["signing","key encipherment","server auth","client auth"]}}}}EOFcat > ca-csr.json << EOF{"CN": "kubernetes","key": {"algo": "rsa","size": 2048},"names": [{"C": "CN","L": "Beijing","ST": "Beijing","O": "k8s","OU": "System"}]}EOF# 生成证书cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
签发 apiserver 的 https 证书
cd /opt/ssl/k8scat > server-csr.json << EOF{"CN": "kubernetes","hosts": ["10.10.0.1","127.0.0.1","192.168.10.11","192.168.10.12","192.168.10.13","192.168.10.14","192.168.10.15","192.168.10.16","192.168.10.17","kubernetes","kubernetes.default","kubernetes.default.svc","kubernetes.default.svc.cluster","kubernetes.default.svc.cluster.local"],"key": {"algo": "rsa","size": 2048},"names": [{"C": "CN","L": "BeiJing","ST": "BeiJing","O": "k8s","OU": "System"}]}EOF
hosts 字段中 IP 为所有 Master/LB/VIP 的 ip,需要访问 apiserver 的节点 ip 建议都写上。
# 生成证书cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
2.2/ apiserver 部署
可从这里 https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG 找到你需要的版本的二进制安装包。直接下载 server 包即可,其中包含有 apiserver、controller manager和scheduler的二进制文件。apiserver 部署步骤如下:
# 获取二进制文件wget https://dl.k8s.io/v1.16.14/kubernetes-server-linux-amd64.tar.gzmkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}tar zxvf kubernetes-server-linux-amd64.tar.gzcd kubernetes/server/bincp kube-apiserver kube-scheduler kube-controller-manager /opt/kubernetes/bincp kubectl /usr/bin/# 创建配置文件cp /opt/ssl/k8s/ca*pem /opt/ssl/k8s/server*pem /opt/kubernetes/ssl/cat > /opt/kubernetes/cfg/kube-apiserver.conf << EOFKUBE_APISERVER_OPTS="--logtostderr=false \\--v=2 \\--log-dir=/opt/kubernetes/logs \\--etcd-servers=https://192.168.10.14:2379,https://192.168.10.15:2379,https://192.168.10.16:2379 \\--bind-address=192.168.10.11 \\--secure-port=6443 \\--advertise-address=192.168.10.11 \\--allow-privileged=true \\--service-cluster-ip-range=10.10.0.0/24 \\--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \\--authorization-mode=RBAC,Node \\--enable-bootstrap-token-auth=true \\--token-auth-file=/opt/kubernetes/cfg/token.csv \\--service-node-port-range=30000-32767 \\--kubelet-client-certificate=/opt/kubernetes/ssl/server.pem \\--kubelet-client-key=/opt/kubernetes/ssl/server-key.pem \\--tls-cert-file=/opt/kubernetes/ssl/server.pem \\--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \\--client-ca-file=/opt/kubernetes/ssl/ca.pem \\--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \\--etcd-cafile=/opt/etcd/ssl/ca.pem \\--etcd-certfile=/opt/etcd/ssl/server.pem \\--etcd-keyfile=/opt/etcd/ssl/server-key.pem \\--audit-log-maxage=30 \\--audit-log-maxbackup=3 \\--audit-log-maxsize=100 \\--audit-log-path=/opt/kubernetes/logs/k8s-audit.log"EOF
logtostderr:启用日志 v:日志等级 log-dir:日志目录 etcd-servers:etcd 集群地址 bind-address:监听地址 secure-port:https 安全端口 advertise-address:集群通告地址 allow-privileged:启用授权 service-cluster-ip-range:Service 虚拟 IP 地址段 enable-admission-plugins:准入控制模块 authorization-mode:认证授权,启用 RBAC 授权和节点自管理 enable-bootstrap-token-auth:启用 TLS bootstrap 机制 token-auth-file:bootstrap token 文件 service-node-port-range:Service nodeport 类型默认分配端口范围 kubelet-client-xxx:apiserver 访问 kubelet 客户端证书 tls-xxx-file:apiserver https 证书 etcd-xxxfile:连接 Etcd 集群证书 audit-log-xxx:审计日志
Master apiserver 启用 TLS 认证后,Node 节点kubelet和kube-proxy要与kube-apiserver进行通信,必须使用 CA 签发的有效证书才可以,当 Node 节点很多时,这种客户端证书颁发需要大量工作,同样也会增加集群扩展复杂度。为了简化流程,Kubernetes 引入了TLS bootstraping机制来自动颁发客户端证书,kubelet会以一个低权限用户自动向apiserver申请证书,kubelet的证书由apiserver动态签署。所以强烈建议在 Node 上使用这种方式,目前主要用于kubelet,kube-proxy还是由我们统一颁发一个证书。
# 生成一个随机tokenhead -c 16 /dev/urandom | od -An -t x | tr -d ' 'ebe4f1e22044e23638394dd24d4aff49# 创建token 文件, 该文件在 apiserver 参数 token-auth-file 参数使用cat > /opt/kubernetes/cfg/token.csv << EOFebe4f1e22044e23638394dd24d4aff49,kubelet-bootstrap,10001,"system:node-bootstrapper"EOF
创建服务管理配置文件
cat > /usr/lib/systemd/system/kube-apiserver.service << EOF[Unit]Description=Kubernetes API ServerDocumentation=https://github.com/kubernetes/kubernetes[Service]EnvironmentFile=/opt/kubernetes/cfg/kube-apiserver.confExecStart=/opt/kubernetes/bin/kube-apiserver \$KUBE_APISERVER_OPTSRestart=on-failure[Install]WantedBy=multi-user.targetEOF
启动
systemctl daemon-reloadsystemctl start kube-apiserversystemctl enable kube-apiserver
授权 kubelet-bootstrap 用户允许请求证书,kubelet 使用该用户来请求 apiserver 证书,该用户稍后部署 kubelet 时会配置。
kubectl create clusterrolebinding kubelet-bootstrap \--clusterrole=system:node-bootstrapper \--user=kubelet-bootstrap
2.3/ kube-controller-manager 部署
创建配置文件
cat > /opt/kubernetes/cfg/kube-controller-manager.conf << EOFKUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=false \\--v=2 \\--log-dir=/opt/kubernetes/logs \\--leader-elect=true \\--master=127.0.0.1:8080 \\--bind-address=127.0.0.1 \\--service-cluster-ip-range=10.10.0.0/24 \\--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \\--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \\--root-ca-file=/opt/kubernetes/ssl/ca.pem \\--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \\--experimental-cluster-signing-duration=87600h0m0s"EOF
master:通过本地端口 8080 连接 apiserver。 leader-elect:当该组件启动多个时,自动选举(HA) cluster-signing-cert-file/–cluster-signing-key-file:自动为 kubelet 颁发证书的 CA,与 apiserver 保持一致
启动管理配置文件
cat > /usr/lib/systemd/system/kube-controller-manager.service << EOF[Unit]Description=Kubernetes Controller ManagerDocumentation=https://github.com/kubernetes/kubernetes[Service]EnvironmentFile=/opt/kubernetes/cfg/kube-controller-manager.confExecStart=/opt/kubernetes/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTSRestart=on-failure[Install]WantedBy=multi-user.targetEOF
启动
systemctl daemon-reloadsystemctl start kube-controller-managersystemctl enable kube-controller-manager
2.4/ kube-scheduler 部署
cat > /opt/kubernetes/cfg/kube-scheduler.conf << EOFKUBE_SCHEDULER_OPTS="--logtostderr=false \--v=2 \--log-dir=/opt/kubernetes/logs \--leader-elect=true \--master=127.0.0.1:8080 \--bind-address=127.0.0.1"EOF
master:通过本地端口 8080 连接 apiserver。 leader-elect:当该组件启动多个时,自动选举(HA)
启动管理配置文件
cat > /usr/lib/systemd/system/kube-scheduler.service << EOF[Unit]Description=Kubernetes SchedulerDocumentation=https://github.com/kubernetes/kubernetes[Service]EnvironmentFile=/opt/kubernetes/cfg/kube-scheduler.confExecStart=/opt/kubernetes/bin/kube-scheduler \$KUBE_SCHEDULER_OPTSRestart=on-failure[Install]WantedBy=multi-user.targetEOF
启动
systemctl daemon-reloadsystemctl start kube-schedulersystemctl enable kube-scheduler
2.5/ 部署其他两个 Master 节点
# 创建etcd 证书目录mkdir -p /opt/etcd/ssl# 复制 apiserver controller-manager scheduler 配置文件及二进制文件scp -r /opt/kubernetes root@192.168.10.12:/opt# 复制etcd 证书文件scp -r /opt/etcd/ssl root@192.168.10.12:/opt/etcd# 复制 systemd 管理文件scp /usr/lib/systemd/system/kube* root@192.168.10.12:/usr/lib/systemd/system# 复制ctl 二进制文件scp /usr/bin/kubectl root@192.168.10.12:/usr/bin# 修改配置文件为对应ipvi /opt/kubernetes/cfg/kube-apiserver.conf...--bind-address=192.168.10.12 \--advertise-address=192.168.10.12 \...# 启动systemctl daemon-reloadsystemctl start kube-apiserversystemctl start kube-controller-managersystemctl start kube-schedulersystemctl enable kube-apiserversystemctl enable kube-controller-managersystemctl enable kube-scheduler
至此,Master 节点部署完成。
3/ Kubernetes Node 节点部署
创建目标,并复制组件二进制文件。
# 创建kubernetes目录mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}# 复制二进制文件scp /root/kubernetes/server/bin/kubelet root@192.168.10.14:/opt/kubernetes/binscp /root/kubernetes/server/bin/kube-proxy root@192.168.10.14:/opt/kubernetes/binscp /root/kubernetes/server/bin/kubectl root@192.168.10.14:/bin/chmod +x /opt/kubernetes/bin/*chmod +x /bin/kubectl# 复制根证书scp /opt/kubernetes/ssl/ca.pem root@192.168.10.14:/opt/kubernetes/ssl
3.1/ kubelet 部署
创建配置文件
cat > /opt/kubernetes/cfg/kubelet.conf << EOFKUBELET_OPTS="--logtostderr=false \\--v=2 \\--log-dir=/opt/kubernetes/logs \\--hostname-override=10-14-node \\--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \\--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \\--config=/opt/kubernetes/cfg/kubelet-config.yml \\--cert-dir=/opt/kubernetes/ssl \\--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0"EOF
hostname-override:显示名称,集群中唯一 network-plugin:启用 CNI kubeconfig:自动生成的配置文件,后面用于连接 apiserver bootstrap-kubeconfig:首次启动向 apiserver 申请证书 config:配置参数文件 cert-dir:kubelet 证书生成目录 pod-infra-container-image:管理 Pod 网络容器的镜像
配置参数文件。
cat > /opt/kubernetes/cfg/kubelet-config.yml << EOFkind: KubeletConfigurationapiVersion: kubelet.config.k8s.io/v1beta1address: 0.0.0.0port: 10250readOnlyPort: 10255cgroupDriver: systemdclusterDNS:- 10.10.0.2clusterDomain: cluster.localfailSwapOn: falseauthentication:anonymous:enabled: falsewebhook:cacheTTL: 2m0senabled: truex509:clientCAFile: /opt/kubernetes/ssl/ca.pemauthorization:mode: Webhookwebhook:cacheAuthorizedTTL: 5m0scacheUnauthorizedTTL: 30sevictionHard:imagefs.available: 15%memory.available: 100Minodefs.available: 10%nodefs.inodesFree: 5%maxOpenFiles: 1000000maxPods: 110EOF
cgroupDriver: 需要与 Docker 的 cgroup 启动一致,这里都是用 systemd。 clusterDNS: DNS 服务器地址,用来做服务名称和 ip 的解析用。service 启动会创建一条服务名和 ip 的解析,直接使用 service 名称就能访问服务,以达到服务发现的效果。这里先填上 ip,后边会部署这个 DNS 服务。
生成 kubelet bootstrap kubeconfig 配置文件, 用来申请 apiserver 证书。
kubectl config set-cluster kubernetes \--certificate-authority=/opt/kubernetes/ssl/ca.pem \--embed-certs=true \--server=https://192.168.10.12:6443 \--kubeconfig=bootstrap.kubeconfigkubectl config set-credentials "kubelet-bootstrap" \--token=ebe4f1e22044e23638394dd24d4aff49 \--kubeconfig=bootstrap.kubeconfigkubectl config set-context default \--cluster=kubernetes \--user="kubelet-bootstrap" \--kubeconfig=bootstrap.kubeconfigkubectl config use-context default --kubeconfig=bootstrap.kubeconfigcp bootstrap.kubeconfig /opt/kubernetes/cfg
创建 system 服务管理文件。
cat > /usr/lib/systemd/system/kubelet.service << EOF[Unit]Description=Kubernetes KubeletAfter=docker.service[Service]EnvironmentFile=/opt/kubernetes/cfg/kubelet.confExecStart=/opt/kubernetes/bin/kubelet \$KUBELET_OPTSRestart=on-failureLimitNOFILE=65536[Install]WantedBy=multi-user.targetEOF
启动
systemctl daemon-reloadsystemctl start kubeletsystemctl enable kubelet
启动之后,在 Master 节点可以看到申请,需要执行如下命令来接受。
# 查看node 加入申请[root@10-11-master]# kubectl get csrNAME AGE REQUESTOR CONDITIONnode-csr-zXbvV_-slQhtuuKZddLIl9H4mKEfOhTkB-8TtaW2Nf8 36s kubelet-bootstrap Pending# 接受申请kubectl certificate approve node-csr-zXbvV_-slQhtuuKZddLIl9H4mKEfOhTkB-8TtaW2Nf8# 查看node[root@10-11-master]# kubectl get nodeNAME STATUS ROLES AGE VERSION75-33-65-shx-node NotReady1s v1.16.0
节点状态为 NotReady,稍后等 kubelet 初始化好后,变为 Ready。有些 kubelet 配置了 cni(容器网络接口)插件,当插件安装之前,不会变为 Ready。
3.2/ kube-proxy 部署
证书签发
cd /opt/kubernetes/sslcat > kube-proxy-csr.json << EOF{"CN": "system:kube-proxy","hosts": [],"key": {"algo": "rsa","size": 2048},"names": [{"C": "CN","L": "BeiJing","ST": "BeiJing","O": "k8s","OU": "System"}]}EOF# 生成证书cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxyls kube-proxy*pemkube-proxy-key.pem kube-proxy.pem
环境变量配置文件
# 环境变量配置文件cat > /opt/kubernetes/cfg/kube-proxy.conf << EOFKUBE_PROXY_OPTS="--logtostderr=false \\--v=2 \\--log-dir=/opt/kubernetes/logs \\--config=/opt/kubernetes/cfg/kube-proxy-config.yml"EOF# 配置文件cat > /opt/kubernetes/cfg/kube-proxy-config.yml << EOFkind: KubeProxyConfigurationapiVersion: kubeproxy.config.k8s.io/v1alpha1bindAddress: 0.0.0.0metricsBindAddress: 0.0.0.0:10249clientConnection:kubeconfig: /opt/kubernetes/cfg/kube-proxy.kubeconfighostnameOverride: 10-14-nodeclusterCIDR: 10.10.0.0/16EOF
systemd 服务管理脚本
cat > /usr/lib/systemd/system/kube-proxy.service << EOF[Unit]Description=Kubernetes ProxyAfter=network.target[Service]EnvironmentFile=/opt/kubernetes/cfg/kube-proxy.confExecStart=/opt/kubernetes/bin/kube-proxy \$KUBE_PROXY_OPTSRestart=on-failureLimitNOFILE=65536[Install]WantedBy=multi-user.targetEOF
启动
systemctl daemon-reloadsystemctl start kube-proxysystemctl enable kube-proxy
至此,Node 节点部署完成。其他 Node 部署相同,修改对应 ip 和 host 即可。
4/ 网络插件部署
安装完 Node 节点组件之后,Pod 内容器是可以通信的,但是 Pod 之间是无法通信的,这就需要 CNI 网络插件了。常用的 CNI 插件有 Calico、flannel、Terway、Weave Net 以及 Contiv。这里选用常用的 Flannel,如何选择 CNI 插件,大家可参考这篇文章 理解 CNI 和 CNI 插件[4]。
CNI 插件的安装方式有两种:
ETCD 方式。这种方式就是利用 etcd 存储网络配置信息,并且利用 dockerd 启动参数 --bip来指定每个节点的网段信息。CNI 插件方式。这种方式是利用 cni 插件,并且将网络配置信息存储在 kubernetes api 中,Kubulet 找到对应的 cni 插件,有插件分配节点 IP 网段。
CNI 插件主要部署在有 Pod 调度的节点,常部署在 Node 节点。
4.1/ CNI 方式安装
CNI 插件方式,首先需要在 Master 各组件增加一些参数。
1/ 修改 controller 参数
在 kube-controller-manager 启动脚本中加入下边两个参数:
--allocate-node-cidrs=true节点允许自动分配网段。--cluster-cidr=10.10.0.0/16为我们指定的集群的网段,这样每一个 docker 节点都会分别使用自网段 10.10.0.0/24,10.10.1.0/24 作为每个 pod 的网段,可以通过kubectl get pod命令查看-o yaml spec.podCIDR字段。
如果不配置该步骤可能会flannel出现error registering network: failed to acquire lease: node "192.168.10.14" pod的错误
2/ 修改 kubelet 参数
指定 kubelet 网络插件,在 kubelet 中指定如下三个参数:
--network-plugin=cni网络插件使用 cni,必须添加,否则默认走 docker 自己的网络。--cni-conf-dir=/etc/cni/net.dcni 配置文件 ,默认--cni-bin-dir=/opt/cni/bincni 可执行文件,默认
这样在 kublet 启动的时候,就会去/etc/cni/net.d 目录查找配置文件,并解析,使用相应的插件配置网络
3/ 下载 cni 依赖插件
下载 cni 官方提供的组件:cni-plugins-amd64-v0.7.1.tgz[5] ,并将可执行文件放在/opt/cni/bin 目录。
这里不单单只会用到 flannel 文件,也会用到 brage 用来创建网桥以及 host-local 用来分配 ip。
这一步不是必须的,当使用 yum 安装 kubelet 时,会自动下载依赖的kubernetes-cni包,并放置到相应位置。
4/ 安装 flanneld 组件
flannel 组件直接以daemonset的方式安装在 k8s 集群中:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlkubectl apply -f kube-flannel.yml
其中kube-flannel-cfg configmap 中的 Network 字段需要与--cluster-cidr配置的网段一致。
这一步主要是安装了flanneld以及将flannel配置文件写入/etc/cni/net.d目录。
查看kube-flannel.yml中flanneld的启动参数为:
--ip-masq : 需要为其配置SNAT--kube-subnet-mgr : 代表其使用kube类型的subnet-manager。该类型有别于使用etcd的local-subnet-mgr类型,使用kube类型后,flannel上各Node的IP子网分配均基于K8S Node的`spec.podCIDR`属性
4.2/ ETCD 方式
ETCD 方式安装Flannel,参数无需修改,可保持之前步骤中的参数。
1/ 创建 Flannel 使用的网段
该方式,网段信息是保存在 ETCD 的,需要我们手动的添加
[root@10-14-node ~]# ETCDCTL_API=2 etcdctl --ca-file=/usr/local/kubernetes/etcd/ssl/ca.pem --cert-file=/usr/local/kubernetes/etcd/ssl/server.pem --key-file=/usr/local/kubernetes/etcd/ssl/server-key.pem --endpoints="https://192.168.10.14:2379,https://192.168.10.15:2379,https://192.168.10.16:2379" set /coreos.com/network/config '{"Network":"10.10.0.0/16","Backend":{"Type":"vxlan"}}'{"Network":"10.10.0.0/16","Backend":{"Type":"vxlan"}}[root@10-14-node ~]# ETCDCTL_API=2 etcdctl --ca-file=/usr/local/kubernetes/etcd/ssl/ca.pem --cert-file=/usr/local/kubernetes/etcd/ssl/server.pem --key-file=/usr/local/kubernetes/etcd/ssl/server-key.pem --endpoints=https://192.168.10.14:2379,https://192.168.10.15:2379,https://192.168.10.16:2379 get /coreos.com/network/config{"Network":"10.10.0.0/16","Backend":{"Type":"vxlan"}}[root@10-15-node ~]# ETCDCTL_API=2 etcdctl --ca-file=/usr/local/kubernetes/etcd/ssl/ca.pem --cert-file=/usr/local/kubernetes/etcd/ssl/server.pem --key-file=/usr/local/kubernetes/etcd/ssl/server-key.pem --endpoints=https://192.168.10.14:2379,https://192.168.10.15:2379,https://192.168.10.16:2379 get /coreos.com/network/config{"Network":"10.10.0.0/16","Backend":{"Type":"vxlan"}}
使用该方式安装时,flannel 仅支持 etcd2 版本的 api,针对 etcd 3+ 需要做下兼容。在 etcd 的启动时添加参数
--enable-v2做兼容。etcdctl 执行时,需要加ETRCDCTL_API=2的环境变量。不做兼容的话,汇报如下错误:Couldn't fetch network config: client: response is invalid json. The endpoint is probably not valid etcd cluster endpoint. timed out, 可见这个issue[6]。
2/ 安装 Flannel
下载二进制文件,https://github.com/coreos/flannel/releases , 这里选用 0.11。
wget https://github.com/coreos/flannel/releases/download/v0.11.0/flannel-v0.11.0-linux-amd64.tar.gztar zxvf flannel-v0.11.0-linux-amd64.tar.gzmv flanneld mk-docker-opts.sh /opt/kubernetes/bin/# 配置文件cat > /opt/kubernetes/cfg/flannel.conf << EOFFLANNEL_OPTIONS="--etcd-endpoints=https://192.168.10.14:2379,https://192.168.10.14:2379,https://192.168.10.14:2379 \\--etcd-cafile=/opt/etcd/ssl/ca.pem \\--etcd-certfile=/opt/etcd/ssl/server.pem \\--etcd-keyfile=/opt/etcd/ssl/server-key.pem"EOF# 添加启动文件cat > /usr/lib/systemd/system/flanneld.service << EOF[Unit]Description=Flanneld overlay address etcd agentAfter=network-online.target network.targetBefore=docker.service[Service]Type=notifyEnvironmentFile=/usr/local/kubernetes/cfg/flannel.confExecStart=/usr/local/kubernetes/bin/flanneld --ip-masq $FLANNEL_OPTIONSExecStartPost=/usr/local/kubernetes/bin/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/subnet.envRestart=on-failure[Install]WantedBy=multi-user.targetEOF# 启动systemctl daemon-reloadsystemctl start flanneldsystemctl enable flanneld
启动之后会在/run/flannel/subnet.env 生成一个子网描述文件,内容如下:
DOCKER_OPT_BIP="--bip=10.10.101.1/24"DOCKER_OPT_IPMASQ="--ip-masq=false"DOCKER_OPT_MTU="--mtu=1450"DOCKER_NETWORK_OPTIONS=" --bip=10.10.101.1/24 --ip-masq=false --mtu=1450"
我们需要将它配置为 Docker 的环境变量,以供 Docker 分配 ip 使用。
[Service]...EnvironmentFile=/run/flannel/subnet.envExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock $DOCKER_NETWORK_OPTIONS...
重启 Docker,以加载新的配置。
systemctl daemon-reloadsystemctl restart docker
至此,Flannel 插件边安装完成了。安装完成后,可通过 ip a看到,自动创建了一个flannel.1 类似名称的虚拟网卡出现,主要用来做 vxlan 报文的处理,封包和解包。
[root@10-14-node ]# ip a1: lo:mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 ,up,lower_up>link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever2: eth0:mtu 1500 qdisc mq state UP group default qlen 1000 ,multicast,up,lower_up>link/ether c4:b8:b4:91:4e:99 brd ff:ff:ff:ff:ff:ffinet 192.168.10.14/24 brd 192.168.10.255 scope global eth0valid_lft forever preferred_lft forever3: eth1:mtu 1500 qdisc noop state DOWN group default qlen 1000 ,multicast>link/ether c4:b8:b4:91:4e:9a brd ff:ff:ff:ff:ff:ff4: docker0:mtu 1500 qdisc noqueue state DOWN group default ,broadcast,multicast,up>link/ether 02:42:26:57:30:53 brd ff:ff:ff:ff:ff:ffinet 10.10.101.1/24 brd 10.10.101.255 scope global docker0valid_lft forever preferred_lft foreverinet6 fe80::42:26ff:fe57:3053/64 scope linkvalid_lft forever preferred_lft forever9: flannel.1:mtu 1450 qdisc noqueue state UNKNOWN group default ,multicast,up,lower_up>link/ether 2a:3c:d8:f4:f9:aa brd ff:ff:ff:ff:ff:ffinet 10.10.101.0/32 scope global flannel.1valid_lft forever preferred_lft foreverinet6 fe80::283c:d8ff:fef4:f9aa/64 scope linkvalid_lft forever preferred_lft forever
在看路由:
[root@75-33-65-shx-node data0]# routeKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Ifacedefault gateway 0.0.0.0 UG 0 0 0 eth010.10.15.0 10.10.15.0 255.255.255.0 UG 0 0 0 flannel.110.10.53.0 10.10.53.0 255.255.255.0 UG 0 0 0 flannel.110.10.66.0 10.10.66.0 255.255.255.0 UG 0 0 0 flannel.110.10.70.0 10.10.70.0 255.255.255.0 UG 0 0 0 flannel.110.10.96.0 10.10.96.0 255.255.255.0 UG 0 0 0 flannel.110.10.101.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0...
除了自身 10.10.101.0的包,其他10.10.0.0/16网段的包都走 flannel.1虚拟网卡。
5/ DNS 服务插件部署
在 K8S 中,DNS 服务主要用来解析 Service 名称和 ip。当有新的 service 时,无需知道它的 ip 直接使用名称即可调用。K8S 目标有两种常用的 DNS 方案,kube-dns 和CoreDNS。CoreDNS从 1.11 起,使用kubeadm 安装 K8S 时,是默认安装的。这里也选择安装 CoreDNS,因为CoreDNS服务是以 pod 的形式运行,所以下边操作只需在一台 Master 上操作即可。
下面开始安装:
# 下载 CoreDNS 项目git clone https://github.com/coredns/deployment.gitcd coredns/deployment/kubernetes
找到 deploy.sh, 修改如下配置:
111 if [[ -z $CLUSTER_DNS_IP ]]; then112 # Default IP to kube-dns IP113 # CLUSTER_DNS_IP=$(kubectl get service --namespace kube-system kube-dns -o jsonpath="{.spec.clusterIP}")114 CLUSTER_DNS_IP=10.10.0.2
默认情况下 CLUSTER_DNS_IP 是自动获取kube-dns的集群 ip 的,但是由于没有部署 kube-dns 所以只能手动指定一个集群 ip。
# 生成 发布文件sh deploy.sh > coredns.yaml# 引用yamlkubectl apply -f coredns.yamlkubectl get svc,pods -n kube-system| grep corednspod/coredns-759df9d7b-gzj5b 1/1 Running 0 22h
测试下:
cat > busybox.yml <apiVersion: v1kind: Podmetadata:name: busyboxnamespace: defaultspec:containers:- name: busyboximage: busybox:1.28.4command:- sleep- "3600"imagePullPolicy: IfNotPresentrestartPolicy: AlwaysEOFkubectl apply -f busybox.ymlkubectl exec -i busybox nslookup kubernetesServer: 10.10.0.2Address 1: 10.10.0.2 kube-dns.kube-system.svc.cluster.localName: kubernetesAddress 1: 10.10.0.1 kubernetes.default.svc.cluster.local
出现以上信息,说明解析正常。
6/ Dashboard 部署
K8S 官方提供了一个 web 的操作界面叫 Dashboard,可以满足基本的资源的创建、配置和修改。下面说下如何安装:
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-beta8/aio/deploy/recommended.yaml# 下载好配置文件,修改service 访问策略为 NodePort,可直接通过node 的ip访问。...spec:ports:- port: 443targetPort: 8443nodePort: 30001 # 新增type: NodePort # 新增...kubectl apply -f recommended.yamlkubectl get pods,svc -n kubernetes-dashboardNAME READY STATUS RESTARTS AGEpod/dashboard-metrics-scraper-76585494d8-hbjj4 1/1 Running 0 8dpod/kubernetes-dashboard-5996555fd8-j5kq9 1/1 Running 0 8dNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/dashboard-metrics-scraper ClusterIP 10.10.130.258000/TCP 8d service/kubernetes-dashboard NodePort 10.10.32.39443:30001/TCP 8d
可通过 https:// 来访问,系统提供了两种任务方式,我们常用 token 认证方式,下边我们来生成 token。
# 创建service admin 账户 dashboard-adminkubectl create serviceaccount dashboard-admin -n kube-system# 绑定集群默认管理员角色 cluster-adminkubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin# 查看登录 tokenkubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
可使用上边输出的 token ,登录 dashboard。
高可用架构
到这里,我们所有节点组件完成。我们的架构如下图:

从图中我们可以看出一个问题,controller-manager 和scheduler可通过etcd间接的通信实现互为备份高可用,而apiserver则没有。架构中所有的 Node 都是连接的一台 Master 的 apiserver,其他两台并没有利用起来,连接的这台一旦出现故障,整个系统便无法使用。这个问题,常用的解决方案是使用 nginx 和 keeplive 实现,架构如下:
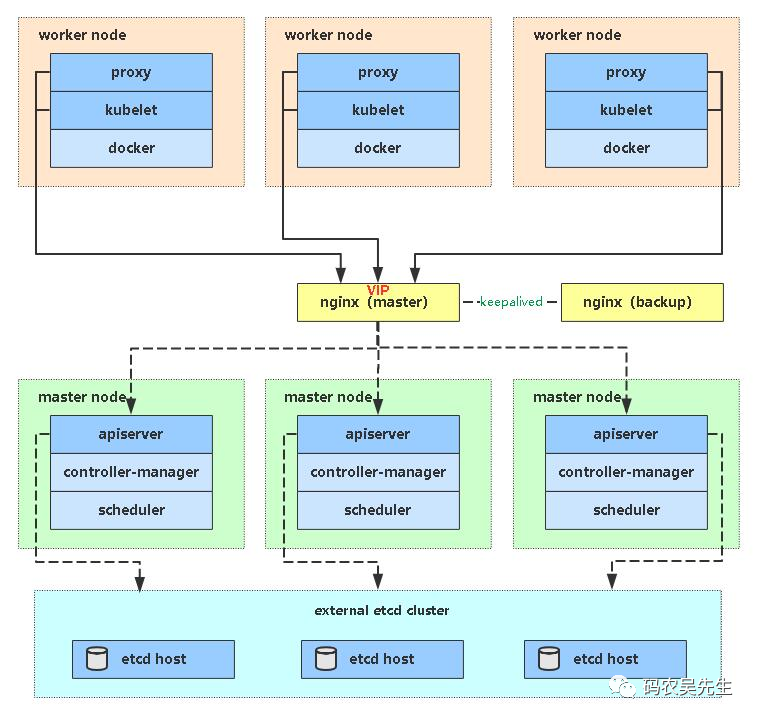
因为需要单独申请 VIP,我并没有做具体搭建,仅使用 nginx 做了负载均衡。需要注意的是,这里 Nginx 用来做四层的负载均衡使用 stream配置段,和http略有不同。
这里简单说下搭建步骤,最少使用两台机器互为主备。
# 安装nginx 和 keepalive。yum install epel-release -yyum install nginx keepalived -y# nginx 配置文件cat > /etc/nginx/nginx.conf << "EOF"user nginx;worker_processes auto;error_log /var/log/nginx/error.log;pid /run/nginx.pid;include /usr/share/nginx/modules/*.conf;events {worker_connections 1024;}# 四层负载均衡,为两台Master apiserver组件提供负载均衡stream {log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';access_log /var/log/nginx/k8s-access.log main;upstream k8s-apiserver {server 192.168.10.14:6443; # Master1 APISERVER IP:PORTserver 192.168.10.15:6443; # Master2 APISERVER IP:PORTserver 192.168.10.16:6443; # Master2 APISERVER IP:PORT}server {listen 6443;proxy_pass k8s-apiserver;}}http {log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';access_log /var/log/nginx/access.log main;sendfile on;tcp_nopush on;tcp_nodelay on;keepalive_timeout 65;types_hash_max_size 2048;include /etc/nginx/mime.types;default_type application/octet-stream;server {listen 80 default_server;server_name _;location / {}}}EOF# keepalive 主机配置文件cat > /etc/keepalived/keepalived.conf << EOFglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_MASTER}vrrp_script check_nginx {script "/etc/keepalived/check_nginx.sh"}vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的priority 100 # 优先级,备服务器设置 90advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒authentication {auth_type PASSauth_pass 1111}# 虚拟IPvirtual_ipaddress {192.168.31.88/24}track_script {check_nginx}}EOF# nginx 检测脚本,主备都需要有cat > /etc/keepalived/check_nginx.sh << "EOF"#!/bin/bashcount=$(ps -ef |grep nginx |egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenexit 1elseexit 0fiEOFchmod +x /etc/keepalived/check_nginx.sh# keepalive 备机配置文件cat > /etc/keepalived/keepalived.conf << EOFglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_BACKUP}vrrp_script check_nginx {script "/etc/keepalived/check_nginx.sh"}vrrp_instance VI_1 {state BACKUPinterface ens33virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的priority 90advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.31.88/24}track_script {check_nginx}}EOF# 启动,并设置开机启动systemctl daemon-reloadsystemctl start nginxsystemctl start keepalivedsystemctl enable nginxsystemctl enable keepalived# ip a ,可以看到 vip 已经绑定到网卡上inet 192.168.31.88/24 scope global secondary ens33valid_lft forever preferred_lft forever
接下里,将所有 Node 节点改为链接 VIP 的apiserver,重启 kubelet 和 kube-proxy 即可。
至此,一个高可用的 K8S 集群便搭建完成了,尽情享用吧。
扩展阅读
1/ 通过 Kubeadm 安装 K8S 与高可用[7] 2/ Kubernetes 中文文档[8] 3/ 详解 DNS 与 CoreDNS 的实现原理[9] 4/ Flannel 网络[10]
参考资料
Kubernetes 学习笔记-基础篇: https://pylixm.cc/posts/2020-08-20-k8s-base.html
[2]安装文档: https://kubernetes.io/docs/setup/learning-environment/
[3]启用文档: https://docs.docker.com/docker-for-mac/#kubernetes
[4]理解 CNI 和 CNI 插件: https://www.kubernetes.org.cn/6908.html
[5]cni-plugins-amd64-v0.7.1.tgz: https://github.com/containernetworking/plugins/releases/download/v0.7.1/cni-plugins-amd64-v0.7.1.tgz
[6]issue: https://github.com/coreos/flannel/issues/1191
[7]1/ 通过 Kubeadm 安装 K8S 与高可用: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
[8]2/ Kubernetes 中文文档: https://www.kubernetes.org.cn/docs
[9]3/ 详解 DNS 与 CoreDNS 的实现原理: https://draveness.me/dns-coredns/
[10]4/ Flannel 网络: https://www.cnblogs.com/goldsunshine/p/10740928.html









