

1057 阅读 2020-12-29 10:13:17 上传
以下文章来源于 十分语言学
疫情之下,全球金融市场进入大波动时代,各国金融调控政策、突发事件层出不穷,例如美联储无限量QE、欧央行7500亿复苏基金、中美关闭使领馆、阿塞拜疆和亚美尼亚爆发空战...如何24*7小时全天候自动、智能监控全球新闻事件,从而最快速地做出反应、最大可能地规避风险?
基于此,本文主要介绍了基于自然语言处理技术的金融舆情事件分析系统,期望构建风险、交易事件信号,助力投资交易、风控领域。
1、人工智能自然语言技术发展简史
自然语言处理(Natural Language Processing , NLP)是一门通过建立形式化的计算模型来分析、理解和处理自然语言的学科,也是一门横跨语言学、计算机科学、数学等领域的交叉学科。具体表现形式包括机器翻译、文本摘要、文本分类、文本校对、信息抽取、语音合成、语音识别等。人类一直在探寻如何通过机器学习理解文本语义,推理文本间的关系,甚至加入联想、创新推理,目前技术主要停留在机器学习理解文本的阶段,也有相关研究人员在研究“事理图谱”等推理领域,但也是刚刚开始。自然语言处理技术的发展经历了
1.初始阶段,时间跨度大概为20世纪50年代到70年代。这个阶段,研究人员主要采用基于规则的方法,研究重点包括机器翻译、自然语言理解等任务。其中,在1956年,Chomsky提出了“生成式文法”的概念,他假设客观世界存在一种自然语言生成规则,一旦总结出这个规律,人类就能掌握自然语言的奥秘。此后,以语言学为基础的符号主义学派占据了主流,大量的研究工作聚焦于从语言学角度分析自然语言的词法、句法等结构信息,并总结出相关的规则,达到理解自然语言的目的。这种研究方式有其必然的缺陷。首先,规则不可能覆盖所有用例,其泛化性无法保证;另外研究者需要对计算机和语言学两门学科都较为精通,这大大提升了研究问题的难度。
2.基于统计方法的发展时期,时间跨度大概为20世纪80年代到21世纪初。70年代末,基于符号主义的自然语言处理研究进展缓慢,未达预期,因此该领域经历了一段时间的沉寂。70年代,基于隐马尔可夫模型(Hidden Markov Model, HMM)的统计方法在语音识别领域获得成功。80年代初,话语分析(Discourse Analysis)也取得了重大进展。之后,由于自然语言处理研究者对于过去的研究进行了反思,有限状态模型(如经典的CRF方法)和经验主义研究方法也开始复苏。
3.深度学习时期,时间跨度为21世纪至今。随着计算机算力的爆炸式增长以及深度神经网络技术的逐渐成熟,研究人员开始研究如何将深度学习技术应用到自然语言处理领域。基于海量的语料数据,结合深度神经网络强大的拟合能力,各项自然语言处理任务的公共评测榜单被逐渐刷新。其中,2013年提出的word2vec技术通过大量文本的自监督训练得到包含丰富语义信息的词向量,自此以后,自然语言处理先后经历了基于序列模型(RNN,LSTM为主)、基于Attention注意力机制的Transformer模型、以ELMO、BERT、GPT为基础的基于大规模语料的预训练语言模型的时期。当前,在很多自然语言处理任务的公开评测榜单上,机器的指标已经超过了人类(如阅读理解等)。
总体来说,自然语言处理的发展经历了多个历史阶段的演进,通过不同领域、学科之间的相互碰撞,才有了当前的成果。目前的深度学习也有难以回避的缺点,例如Alan Kay表示,即便我们拥有巨量神经元构成的神经网络和专用的芯片,目前AI做的一切不过是 Judea Pearl 所说的 “曲线拟合”(curve fitting),无论是通过多项式这样的最简单的模型来完成,还是通过最复杂的深度神经网络模型来达成,曲线拟合都仅仅是在输入数据和输出数据之间找到某种固定的模式,而非 “理解” 数据。Judea Pearl 是贝叶斯网络的发明者,也是2012年图灵奖的获得者。他现在致力于让机器能够理解因果关系,而不仅仅是数据之间的相关性。所以,自然语言处理技术如何能够和人类一样拥有小样本学习、迁移学习、联想推理能力、实时纠错的能力,仍是未来摆在自然语言处理技术领域尚待解决的难题。
2、金融自然语言类型风险监测、智能投研的行业发展
| 国外 | alphasense、kensho、阿拉丁、Palantir、dataminr、econob |
| 国内 | 蚂蚁金服、通联数据、香侬科技、灵矶互联、京东数科JT2 |
自然语言处理技术特别是深度学习作为一种新兴技术的发展过程中,金融结合自然语言处理形成了“智能投研”的结合点。目前全球范围内的智能投研还处于发展初期。美国在智能投研领域率先进行了探索。早在2000年,黑石集团就开始开发Aladdin(阿拉丁)系统,使用自然语言处理技术对风险进行监测、对文档进行智能解析,提供风险管理和投资咨询信息服务。经过20年的发展,已形成了较高知名度的几家头部企业如AlphaSense、Kensho、DataMinr等。在《全球金融科技权威指南》一书中提到了Econob公司,这家公司也是做自然语言处理落地的公司,他们开发了一套ATRAP系统,可以通过实时新闻来交易,例如如果IBM公司的盈利情况没有达到250亿美金的预期时,他们会卖出IBM股票,反之则会购买股票。每当新闻发布,ATRAP系统便会稽查事实,如果满足了这些条件,它将会自动在市场上下单。另外识别评级事件也是可能实现的,未来也可以实现更通用的事件,例如政治事件、公司合并、CEO离职甚至自然灾害,都是通过自动化软件去识别。一旦有这类高风险事件发生,软件就会立即提示或通知交易者。
2004年,Palanti通过融合多源数据,构建互联数据网络,从中发掘出事物隐藏联系。他们因帮助CIA反恐及找到本拉登而声名鹊起。
2010年,Alphasense通过整理碎片信息,为用户提供金融信息搜索,被称为投资者的Google。
2013年,Kensho以问答的形式为用户提供投资建议,被誉为金融投资领域的问答助手Siri他们构建了一个名为Warren的问答引擎,通过监测财报发布、全球数据环境、经济报告、公司产品发布、FDA药品批准等等90000类事件,建立起事件与资产之间的相关性,从而预测资产价格走势。后续该公司还构建了名为“Visallo”的关系图谱,能够识别并通过Web可视化的方式呈现海量文本中的实体关系。
国内蚂蚁金服收购的玻森数据“风报”系统,通过自然语言处理技术来识别金融主体的风险事件,来进行风险监测。
2016年,通联数据发布萝卜投研,产品包括智能咨询、智能搜索等功能。同期,嘉实基金、华夏基金开始探索智能投研领域。
2018年,京东数科组建资管团队,建设JT2智能资管系统,应用自然语言处理技术来识别相关企业主体的信用、舆情风险,以及金融文档的核心指标要素。
同年,华泰AI团队-开发了一套基于大数据采集分析的金融舆情风险识别监测系统。
3、用户场景分析
随着证券行业对舆情数据监测与分析的需求与日俱增,结合金融投研和风控逻辑对全景舆情数据进行深度挖掘和分析逐渐成为了行业人员的研究重点。本产品针对新闻、公告、社交媒体等舆情数据,基于自然语言处理技术,从不同维度分析舆情数据的情感、观点与态度,面向投资、风控、融资融券等业务,提供及时准确的量化因子、事件驱动信号、投资标的风险评估等服务。
3.1自营投资业务
在自营投资业务中,由于负面舆情对上市公司的投资情绪影响较大,因此对持有重仓的客户提供标的相关的负面舆情推送,能够让客户及时调整持仓,避免大额损失;在量化投资领域,舆情的情感因子可以作为多因子选股或量化择时模型的输入因子,参与量化建模。另外,可以直接通过新闻事件建立事件驱动型策略,获取超额收益,或者在由事件带来的单边趋势中进行换手,增厚收益。
舆情系统已成功多次及时感知到全球的金融事件(5分钟以内),例如“美国发布无限量QE”,5分钟后全球金价在美联储政策发布后急速拉升,“欧洲央行救助计划发布”后,欧元兑美元人民币汇率、Comex金价创下近九年新高。
3.2 风险管理业务
在风险管理业务中,为防范操作风险,必须不断扩充信用违约等事件主体,健全信用风险黑白名单库。舆情系统可以提供信用事件识别和主体抽取服务,解放大量基础的信息收集工作。在融资融券业务中,标的券评估会用到标的相关的负面舆情热度,参与标的券的质地评估,风险事件还可以帮助业务人员在贷后管理中对客户进行监控。在反洗钱业务中,需要对违法、走私、贿赂、涉黑、异常交易等特定事件进行实时监控、智能预警。
3.3 投资银行业务
在投资银行业务中,舆情系统在承揽阶段会主动检索已合作公司和潜在客户的舆情信息,了解该公司是否有重大负面信息。在执行各个业务环节时,也会对项目相关的客户舆情信息进行被动监测。在合规质控环境,会对项目有关公告、违法违规、行政处罚等舆情事件进行查询和检测。
4、金融风险监测技术框架
4.1 用户监控点分析
通过综合投资、风控、投行等业务线的用户求和业务场景,分别从公司、行业、宏观和突发事件四大维度建设监控体系。其中,公司维度应用频度相对较高,具体细分为公司治理类、资质优势类、财务业绩类等。宏观和行业维度主要应用在投研业务中,例如行业研究、信用评级等,分别从宏观研究和各样也研究框架出发进行舆情监控设置。突发事件主要针对一些政治军事、突发事件、自然灾害等,这类事件影响广泛,但是发生频度较小,所以对监控的时效性要求最高。
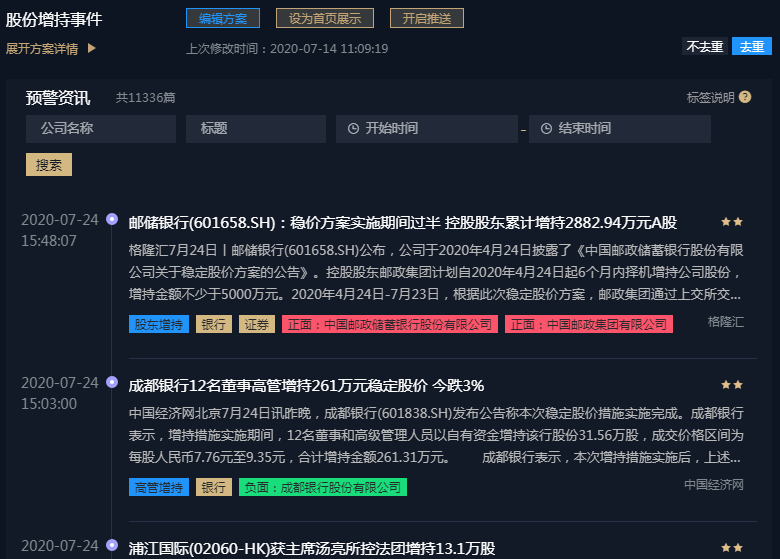
下图为对样本公司的负面舆情监控展示,事件标签为个股下跌:
4.2 架构图和流程图及其概述
舆情系统主要包括:新闻采集平台、统一算法分析平台、知识管理后台和数据展示等部分。

新闻采集平台底层基于分布式高吞吐网络采集系统,配合完善的采集配置、调度和监控平台,实现了2万+热点金融新闻站点的实时更新采集。原始新闻网页获取后,平台可根据配置规则精准抽取新闻相关内容,配合智能数据清洗过程,最终输出高质量的新闻数据。
统一算法分析平台,是一套可以灵活的整合底层算法服务库,并提供数据流处理、任务处理、算法调优、异常监控等全方位的数据分析支持。
5、舆情系统核心算法模块
针对舆情大数据分析需求,我们在底层算法积累的基础上,研发了更面向应用层的算法组件。其中金融主体识别、主体情感、事件要素抽取是其中非常核心的组件。
5.1 热点话题聚类
热点话题聚类模块的主要功能为针对最近一段时间抓取到的各大财经网站上的财经新闻内容,分析这些新闻内容包含的主题信息,并将这些新闻根据主题信息进行聚类,并根据各个主题的热度,筛选出热度最高的主题新闻展示给用户。用户通过热点话题,能够快速了解当前全球热点事件,包括国家重要政策、行业热点、公司的热门事件报道等。
该模块主要基于无监督的主题聚类算法,并辅以实体识别技术,结合一些人工规则特征。核心流程如下图所示:

具体描述如下:
1.话题抽取:针对短文本的新闻标题,基于传统主题模型LDA(Latent Dirichlet allocation)不适用于短文本的前提,我们选择了专门针对短文本的主题建模算法BTM(Biterm Topic Model),它的核心思想是将所有标题文本集合成一个文档,通过提取Biterm词对,对整个集合文档计算一个主题概率分布,避免了传统主题模型的稀疏性问题。
2.话题聚类:根据BTM主题模型的主题抽取结果,对所有新闻标题进行聚类,聚类的算法采用了xmeans,相对于传统的kmeans算法,该算法不需要指定聚类的数量,只需要给定聚簇数量的大致范围,根据聚类的质量指标迭代选择最优的聚簇数。
3.聚类后处理:由于主题模型和聚类算法的能力限制,得到的新闻聚类结果并不十分理想。存在冗余聚类、异常点等情况。因此,需要对聚类结果进行后处理。主要工作为结合已有的实体识别模型,识别新闻标题中的主体,根据主体信息将两个相似聚类进行合并,同时根据预先制定的关键词黑名单过滤掉一些用户不关注的主题,最终得到高聚合、低耦合的聚类结果。
4.话题描述生成:我们基于TextRank算法,对所有新闻标题进行了摘要抽取,并结合字数、实体等相关规则特征,选取最合适的新闻标题作为该话题的描述。最终得到的描述既与主体相关,阅读也比较通顺,提升了用户的体验。
5.历史话题合并:对历史的话题描述文本进行文本相似度计算,并根据相似度合并冗余度高的话题。鉴于模块性能的要求,我们主要基于文本词的tfidf特征向量化两个文本,并计算其余弦相似度作为其相似度分数。
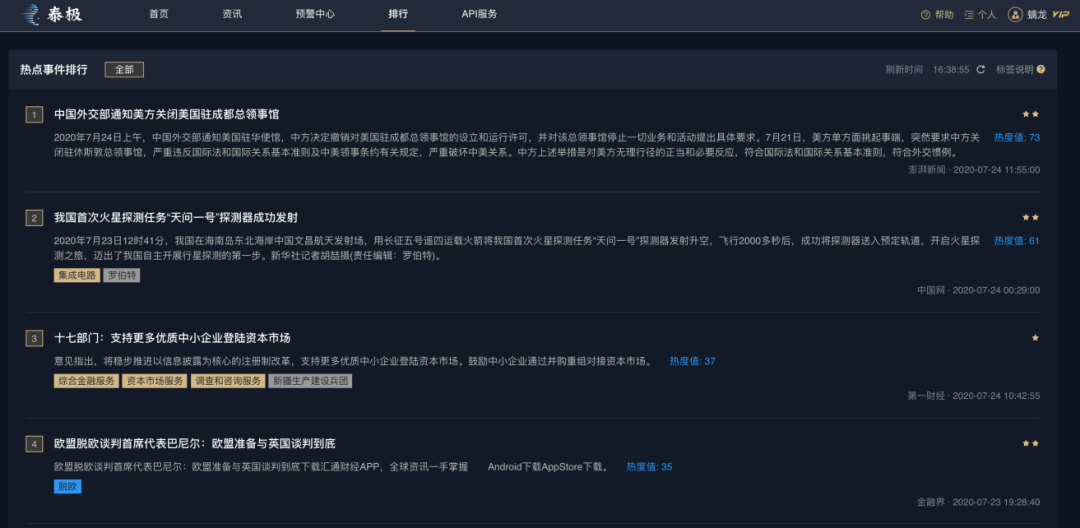
下图为热点话题展示结果:
5.2金融主体识别
金融主体识别模块主要功能是从金融新闻中抽取出实体公司信息,并与知识库中的公司信息建立链接关系,帮助用户准确关联新闻描述的具体公司,高效获取信息。
目前新闻主体识别涉及到的公司主体数量120万+,1000+个新闻源上公司主体识别准确率达到90%+,召回率接近80%。
金融主体识别算法具体分三步进行,核心步骤如图所示:

具体描述如下:
1.实体识别:首先通过通用NER(Named Entity Recognition)与实体词表结合的方式,发掘文本中潜在的金融主体。通用NER采用了百度的LAC工具,根据其分词的边界以及自定义的实体名称识别出实体信息。本步骤的主要目标是提高主体识别的召回率。
2.实体消歧:实体消岐模块运用多种规则知识库,结合NLP技术,对公司关联歧义进行消解,提升关联准确度。其中,规则知识库分为三个粒度,分别为定制规则与统计规则库,用于进行硬规则消歧;公共知识库针对各类公司资讯不同描述方式,总结了通用描述性的语料;实体级知识库包含了每个实体个性化的属性和描述等。三种知识库以串联的方式按顺序分别匹配,若遇到未匹配的实体则进入下一级规则的匹配。其中,在公共知识库的匹配过程中,需要对文本句子进行编码,然后进行相似度匹配。这里的核心技术点为如何对句子进行编码。这里借鉴了triplet loss的思想,如下图所示:
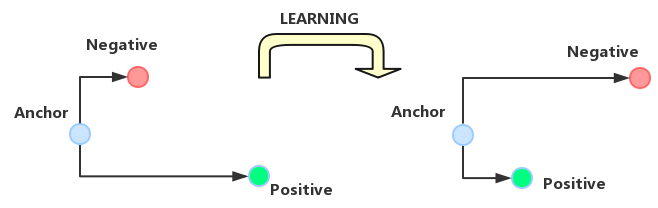
具体来说就是构建三元组,包括基准正例、与基准相似的正例(Anchor)以及一个和基准不同的负例,通过构建triplet loss训练模型,最终使用模型的中间隐层作为编码向量。
3.主体识别:在最后输出主体信息时,首先会通过黑名单的方式过滤敏感金融主体,其次会综合金融主体的检索热度、主体在文本中的统计性特征分数(如tfidf等)、注册信息等进行重要性排序。
5.3金融主体情感分类
本模块主要是通过金融新闻文本的分析,解析出该新闻中对于某个具体实体的情感导向,分为正面情感、负面情感以及中性情感。通过主体的情感分析,能够帮助用户快速识别某个公司实体在某个新闻事件中的情感角色,辅助用户分析该公司实体利好、利空消息。
本模块主要基于BERT预训练模型。BERT结合了每个位置的上下文信息,引入了注意力机制,通过在大规模无监督语料中训练,可以得到更好的语言模型。我们在BERT上探索出了基于span的联合主体抽取和情感分类任务。模型架构图如下:
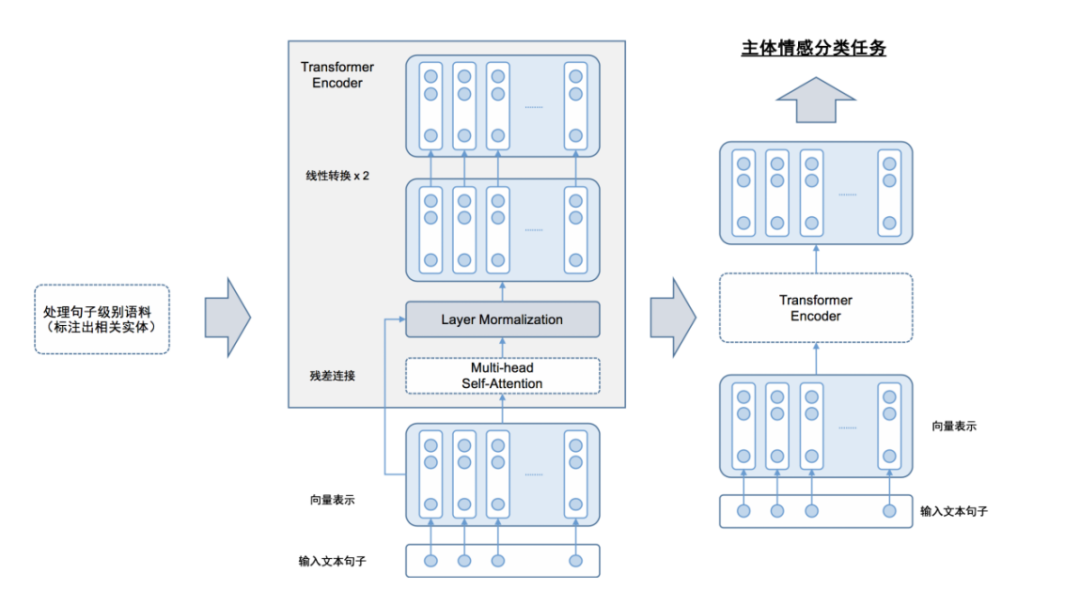
我们借助BERT在训练过程中使用的Next Sentence Prediction任务。构造关于金融主体的辅助句,将文本和金融主体转化为问答对的形式输入到BERT中,具体做法是在输入端将目标金融主体拼接到文本的后面,并使用专门的隔断字符标记[SEP]隔断,最后使用BERT输出层上对应[CLS]位置的张量表示做情感分类。
另外,对于训练数据的标注需要确定各金融主体类别的含义,尽可能涵盖可能出现的金融主体,并排除类别重叠的情况。标注完成之后,需要检验标注质量。
主体情感的效果展示如下:

5.4 事件要素抽取
事件要素抽取主要针对公告内容,检测关注的事件类型,并针对不同事件抽取相应的要素,如主体、客体、时间等。公告事件抽取模块核心步骤如图:

具体描述如下:
1.预处理阶段:将公告的原始数据pdf文件进行文本化和结构化(也称为篇章结构化分析)。系统不仅要将pdf中的表格识别出来,还需要将断句文本进行合并。这里用到了一些规则,包括识别表格边框、行列分隔的位置等,同时构建了一个二分类任务,即将任意两行的文本组成一个样本对,基于BERT模型进行训练,预测两行文本是否应当合并。
2.句子级事件抽取方法:针对不同的公告文本格式,我们设计了两种类型的事件元素抽取方式。对于结构化文本,我们通过设计模板规则,针对具体的表项抽取对应的信息;对于非结构化文本,我们设计了基于BERT+CRF的序列标注模型,将事件类型与事件要素结合,使用BIO标注方式将事件抽取任务转化为序列标注任务,同时我们结合了模板规则,对模型抽取的结果进行后处理,提升模型的准确率。模型的主体架构如图所示:

3.篇章级事件对齐:在做完句子级的事件抽取工作后,需要将公告内的所有事件抽取结果进行整合,关联事件要素与事件主体。这里,我们参考了多文档QA任务的方法,对于每个句子抽取出来的事件,都会有一个预测的概率分数,这个概率分数由句子级事件抽取模型得到,我们在文章全局范围内对相同事件文本的分数进行累加,然后对所有要素进行softmax归一化处理,这样每个要素都能得到一个0到1之间的概率分数,我们通过这个分数来选择所需的事件要素。
4.归一化:这里的归一化特指将抽取出来的事件要素文本描述归一化,如对于金额数字单位、时间、区间范围等进行格式上的统一。
当前临时公告重点事件涉及到91+种证监会规定的事件类型,目前能够自动结构化的事件类型所覆盖的文档数量约占所有重点事件文档数量的90%+,临时公告结构化在业绩快报、业绩预告、利润分配预案、业绩预告更正、购买理财产品、高管辞职、股份质押、董事会决议、定期经营数据等事件类型上的事件要素抽取的f1值达到了0.9以上。
下图为股东减持的事件要素抽取结果展示:

5.5 辅助标注技术
辅助标注技术主要针对的文本结构化任务,如金融公告、内部审阅文书等任务。应用自然语言模型做文本结构化任务时通常会面临以下问题:文本内容复杂多样,相应的语料标注工作会消耗大量人力。
为了解决上述问题,我们采用了一种标注方式,通过对少量样本进行标注后,通过无监督的方法,将标注规则拓展到其他样式文本中,使得标注工作更加自动化,大大提升语料标注的效率。该技术主要核心步骤如下图:

具体描述如下:
1.文档预处理:模块支持多种文件类型包括pdf、docx、html、txt、xlsx等日常办公文档。首选需要对文档进行预处理,预处理的主要工作包括文档清洗和内容拆分。文档清洗主要是做样式清楚,比如docx、html文档中的标签、颜色、字体,pdf的坐标信息等;文本内容拆分则是根据空格、分隔符、换行符等非有效内容字符将文本进行拆分,拆分出来的每个字符串都作为下一步骤提取特征的基本元素。
2.特征生成与转换:我们对步骤1中拆分出来的字符串分别设计海量的特征,用于组成向量表征一个段文本。这些特征包含但不限于:文本的n-gram特征、文本所在的行信息特征、文本在文档中的位置特征、表格行列分隔信息特征等。将这些特征进行组合之后,为每一段文本生成一个向量表示。
3.自动标注:对新的文本进行标注时,我们先对该文本进行步骤1和步骤2的操作,获得文本子串的向量表示,然后我们将所有文本子串的向量与历史库中已有的文本子串向量表示进行相似度计算,结合了余弦相似度、欧式距离、曼哈顿距离等相似度计算方法,根据设定的阈值若找到对应的相似子串,则根据历史文本子串的标注方式自动为当前的文本子串进行标注;若没有找到对应的相似子串,则由标注人员对其进行人为标注,并将该标注信息存储入库。通过上述方式,我们能够为相似特征的子串进行自动标注,标注人员的工作成本大大降低。
5.6 智能财经快讯
智能财经快讯模块主要功能是针对上市公司的年报、季报等财务数据,通过机器自动编写相关财务简讯,并快速向用户进行发布推送,使得用户能够在尽量早的时间获取上市公司的最新财务情况,辅助用户进行财务决策。另外,本模块的用户还包括了证券研究员,通过本模块,研究员能够从繁琐的公告阅读与统计中解放出来,提升其研究的效率。
目前财务快讯生成模块的核心步骤如下图:

具体描述如下:
1.公告结构化抽取:本模块主要专注于将上市公司财报中的结构化数据抽取出来,生成对应的数据表。该模块与事件要素抽取模块较为相似,具体流程不再赘述。
2.基于模板的文本生成:在冷启动阶段,我们基于模板规则的方式生成财务快讯。首先我们根据财报的结构化数据,对每种财务数据栏目设计对应的模板话术,并建立模板映射,例如对于营业收入栏目,可以设计模板“公司当期实现营业收入{营业收入金额},相较于去年同期,增长了{百分点}”,在生成文本时,只需要在槽位中填入对应的财务数据即可。
3.步骤2中基于规则模板的方式生成财务快讯虽然正确性较好,但其多样性是欠缺的,且生成的文本风格往往过于单一。我们设计了两种方法来解决上述问题:1)基于seq2seq序列生成架构,通过构建多样化的快讯文本训练样本。训练一个深度神经网络,生成多样化风格的话术模板,同时将财务数据填充作为一个另外一个槽位填充任务与序列生成任务组成一个pipeline流水线,最后生成多样正确的财务快讯,为了提升多样性,在seq2seq的解码阶段时,我们使用了基于采样的top-k编码方式,在每个位置上进行采样时,从概率分数最高的k个词中进行抽样;2)基于CVAE(条件变分自编码),将多样化的风格作为条件整合到变分自编码模型中,相比于seq2seq模型,能生成更加多样化的文本。
通过上述方法,舆情系统可以在定期公告发布后几分钟内提取其中的财务指标,并形成一篇简要财务报道。对比系统自动生成的财务快讯、财联社快讯和人工采编媒体,时效性差异如下:



6、未来展望
在最近十年,随着深度学习的蓬勃发展,自然语言处理技术也处在历史发展的黄金时期,随着以BERT为代表的大规模预训练模型的广泛应用,许多领域都取得了突破性的进展,尤其是在金融领域,自然语言处理越来越多得被应用投资决策、风险控制、文档自动审核、智能客服等场景。然而,当前自然语言处理领域还存在着诸多问题,例如模型可解释性问题、缺少逻辑推理能力、依赖大量标注数据等,相应的也有很多研究试图解决上述问题,例如研究小样本的模型训练、在深度神经网络中引入先验的专家知识(如知识图谱)等等,我相应会有越来越多的人投身于上述研究,共同推进自然语言处理技术的发展。
总的来说,自然语言处理技术的未来是非常值得期待的,我们有理由相信,它会给各行各业带来前所未有的变化,同时也能够解放人类的生产力,推进人类社会的发展,让我们拭目以待。
参考文献
[1] Xiaohui Yan, Jiafeng Guo, Yanyan Lan, Xueqi Cheng. A Biterm Topic Model for Short Texts. 2013 Proceedings of the 22nd international conference on World Wide Web
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. 2019
[3] Florian Schroff, Dmitry Kalenichenko, James Philbin. FaceNet: A Unified Embedding for Face Recognition and Clustering 2015
[4] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning with Neural Networks 2014
[5] Jurafsky D, Martin JH. Speech and Language Processing. 2nd edn. Englewood Cliffs, NJ: Prentice-Hall, 2008.










